前言 今天来介绍下LinkedList,在集合框架整体框架一章中,我们介绍了List接口,LinkedList与ArrayList一样实现List接口,只是ArrayList是List接口的大小可变数组的实现,LinkedList是List接口链表的实现。基于链表实现的方式使得LinkedList在插入和删除时更优于ArrayList,而随机访问则比ArrayList逊色些。
linkedlist:增 速度快 succ);速度快 速度快
删 速度快
改 相对arraylist速度慢
查 相对arraylist速度慢
#存储的值可以为null
#以下是基于1.6与1.8做的对比
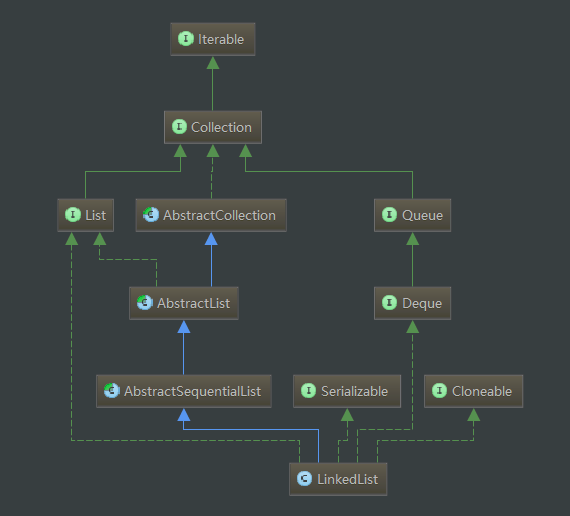
构造图如下:
蓝色线条:继承
绿色线条:接口实现
正文 LinkedList是基于链表结构的一种List,在分析LinkedList源码前有必要对链表结构进行说明。
1.链表的概念
链表是由一系列非连续的节点组成的存储结构,简单分下类的话,链表又分为单向链表和双向链表,而单向/双向链表又可以分为循环链表和非循环链表,下面简单就这四种链表进行图解说明。
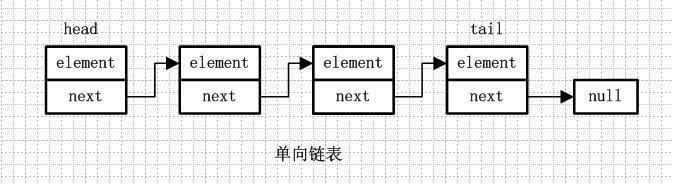
1.1.单向链表
单向链表就是通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
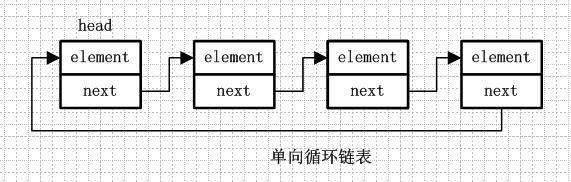
1.2.单向循环链表
单向循环链表和单向列表的不同是,最后一个节点的next不是指向null,而是指向head节点,形成一个“环”。
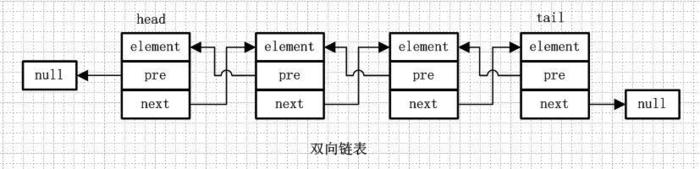
1.3.双向链表
从名字就可以看出,双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。1.8使用的是双向链表
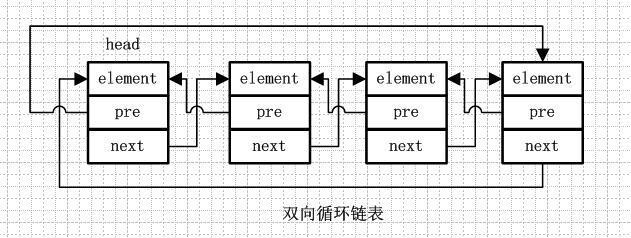
1.4.双向循环链表
双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。而LinkedList就是基于双向循环链表设计的。(1.8则是双向链表)
更形象的解释下就是:双向循环链表就像一群小孩手牵手围成一个圈,第一个小孩的右手拉着第二个小孩的左手,第二个小孩的左手拉着第一个小孩的右手。。。最后一个小孩的右手拉着第一个小孩的左手。
ok,链表的概念介绍完了,下面进入写注释和源码分析部分,但是在这之前还是要提醒一句,不是啰嗦哦,链表操作理解起来比数组困难了不少,所以务必要理解上面的图解,如果源码解析过程中遇到理解困难,请返回来照图理解。
LinkedList简介 LinkedList定义 1 2 3 public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList 是一个继承于AbstractSequentialList的双向循环链表 。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
LinkedList属性 明白了上面的链表概念,以及LinkedList是基于双向循环链表设计的,下面在具体来看看LinkedList的底层的属性
1 2 3 4 5 2 private transient int size = 0; private transient Entry<E> header = new Entry<E>(null, null, null);//1.8版本取消了当前属性 更改为如下: //1.8 : transient Node<E> first; //1.8 : transient Node<E> last;
LinkedList中提供了上面两个属性,其中size和ArrayList中一样用来计数,表示list的元素数量,而header则是链表的头结点,Entry则是链表的节点对象。
1 2 3 4 5 6 7 8 9 10 private static class Entry<E> { //1.8改名为Node E element; // 当前存储元素 //1.8改名为item Entry<E> next; // 下一个元素节点 Entry<E> previous; // 上一个元素节点 //1.8改名为prev Entry(E element, Entry<E> next, Entry<E> previous) { //1.8:Node(Node<E> prev, E element, Node<E> next) { this.element = element; this.next = next; this.previous = previous; } }
Entry为LinkedList 的内部类,其中定义了当前存储的元素,以及该元素的上一个元素和下一个元素。结合上面双向链表的示意图很容易看懂。
LinkedList构造函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /** * 构造一个空的LinkedList . */ public LinkedList() { //将header节点的前一节点和后一节点都设置为自身 header.next = header. previous = header ; //1.8取消了当前行代码,构造里为空代码块 } /** * 构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列 */ public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
需要注意的是空的LinkedList构造方法,它将header节点的前一节点和后一节点都设置为自身,这里便说明LinkedList 是一个双向循环链表,如果只是单存的双向链表而不是循环链表,他的实现应该是这样的:
1 2 3 4 public LinkedList() { header.next = null; header. previous = null; }
非循环链表的情况应该是header节点的前一节点和后一节点均为null(参见链表图解)。
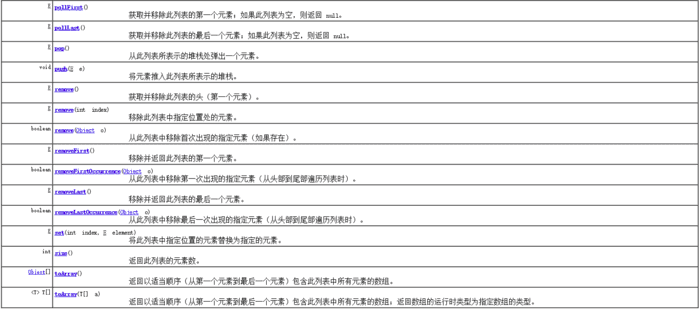
API方法摘要
LinkedList源码解析(基于JDK1.6.0_45) 增加 增加方法的代码读起来比较不容易理解,需要的时候请结合链表图解。
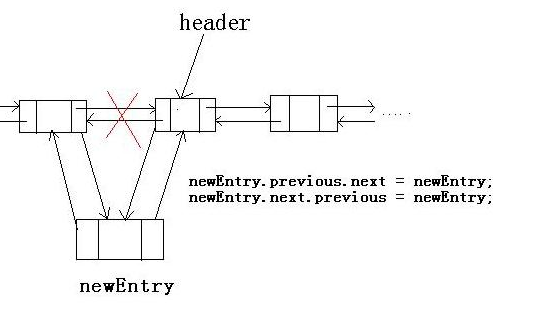
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 /** * 将一个元素添加至list尾部 */ public boolean add(E e) { // 在header前添加元素e,header前就是最后一个结点啦,就是在最后一个结点的后面添加元素e addBefore(e, header); //1.8更改为: //linkLast(e); return true; } /** * 在指定位置添加元素 */ public void add(int index, E element) { // 如果index等于list元素个数,则在队尾添加元素(header之前),否则在index节点前添加元素 addBefore(element, (index== size ? header : entry(index))); //1.8更改为: // checkPositionIndex(index); // if (index == size) // linkLast(element); // else // linkBefore(element, node(index)); } private Entry<E> addBefore(E e, Entry<E> entry) { // 用entry创建一个要添加的新节点,next为entry,previous为entry.previous,意思就是新节点插入entry前面,确定自身的前后引用, Entry<E> newEntry = new Entry<E>(e, entry, entry.previous); // 下面修改newEntry的前后节点的引用,确保其链表的引用关系是正确的 // 将上一个节点的next指向自己 newEntry. previous.next = newEntry; // 将下一个节点的previous指向自己 newEntry. next.previous = newEntry; // 计数+1 size++; modCount++; return newEntry; } 下方为1.8的method: private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } private boolean isPositionIndex(int index) { return index >= 0 && index <= size; } //二分查找 //首先查看是否index和链表大小相等,如果相等直接插入最后(linkLast(E e)方法),如果不等, 取出index对应的元素,把要插入的放的index元素的前面。这个在查找index对应元素的时候有个小技巧, 先看index和二分之一size的大小,如果小于就查找index之前的部分,如果大就从后查找后半部分, 这样最坏只查找一半的元素。 首先判断index值是不是小于整个链表长度的一半,整个if/else逻辑是在判断要插入的位置是距离链 表头近还是链表尾近,目的更快的找到原来index处的节点并返回。 Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; //size=9 size==0 则取出第一个节点 size==9则inkLast(E e) 插入队尾 其余则根据循环 次数的索引来取出对应的节点 //i<9 i最大==8 0~8 ==9 for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } //添加到队尾的方法:先取出来队尾对象,然后把新元素设置队尾, 在让原来对象的next 指向现在的对象,链表长度加1. void linkLast(E e) { //1.获取尾部节点 final Node<E> l = last; //2.创建新节点,并把新节点的上一个节点prev指向上述的1. final Node<E> newNode = new Node<>(l, e, null); //3.把尾部节点指向上述的2. 新节点的prev指向了上一个尾部节点,形成链表结构 last = newNode; //第一条数据,所以设置第一个节点。last与first指向了同一个对象地址,所以在之后添加 节点的时候,修改前一个last的next指向当前队尾时,first的next也同样做了修改。 if (l == null) first = newNode; //把上一个尾部节点的next指向新的尾部节点,形成链表结构 else l.next = newNode; size++; modCount++; } void linkBefore(E e, Node<E> succ) { //截断(插入位置元素:(node(int index) )): 1.插入位置元素的prev把 next设置为newNode 2.newNode的prev设置为插入位置元素的prev,next设置为插入位置元素 3.插入位置元素的prev设置为newNode // assert succ != null; //当前要插入位置节点的上一个节点 final Node<E> pred = succ.prev; //newNode 将要插入的对象包装成node节点(指定上一个节点为pred, //下一个节点为node()返回值succ final Node<E> newNode = new Node<>(pred, e, succ); //接着将succ节点的上一个节点指定为我们的新节点newNode。 succ.prev = newNode; //那么肯定会有逻辑将pred的next设置为newNode。果然,最后做了一个判断, 如果pred为null,说明succ节点为第一个有数据的节点,就将生成的新节点newNode 置为first节点,否则指定上个节点的下一个节点为生成的新节点,即pred.next = newNode。 if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }
到这里可以发现一点疑虑,header作为双向循环链表的头结点是不保存数据的,也就是说hedaer中的element永远等于null 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 /** * 添加一个集合元素到list中 */ public boolean addAll(Collection<? extends E> c) { // 将集合元素添加到list最后的尾部 return addAll(size , c); } /** * 在指定位置添加一个集合元素到list中 */ public boolean addAll(int index, Collection<? extends E> c) { // 越界检查 //1.8更改为: checkPositionIndex(index); if (index < 0 || index > size) throw new IndexOutOfBoundsException( "Index: "+index+ ", Size: "+size ); Object[] a = c.toArray(); // 要插入元素的个数 int numNew = a.length ; if (numNew==0) return false; modCount++; // 找出要插入元素的前后节点 // 获取要插入index位置的下一个节点,如果index正好是lsit尾部的位置那么下一个节点就是header,否则需要查找index位置的节点 Entry<E> successor = (index== size ? header : entry(index)); // 获取要插入index位置的上一个节点,因为是插入,所以上一个点击就是未插入前下一个节点的上一个 Entry<E> predecessor = successor. previous; // 循环插入 for (int i=0; i<numNew; i++) { // 构造一个节点,确认自身的前后引用 Entry<E> e = new Entry<E>((E)a[i], successor, predecessor); // 将插入位置上一个节点的下一个元素引用指向当前元素(这里不修改下一个节点的上一个元素引用,是因为下一个节点随着循环一直在变) predecessor. next = e; // 最后修改插入位置的上一个节点为自身,这里主要是为了下次遍历后续元素插入在当前节点的后面,确保这些元素本身的顺序 predecessor = e; } // 遍历完所有元素,最后修改下一个节点的上一个元素引用为遍历的最后一个元素 successor. previous = predecessor; // 修改计数器 size += numNew; return true; } //下方为 1.8方法: public boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index);// 越界检查 Object[] a = c.toArray(); int numNew = a.length;// 要插入元素的个数 if (numNew == 0) return false; // 找出要插入元素的前后节点 Node<E> pred, succ; if (index == size) { //1 外部调用一个参数的方法之后,由内部方法调用当前方法 succ = null; pred = last; } else {//2 外部指定参数调用 //截断(插入位置元素:(node(int index) )): 1.插入位置元素的prev把 next设置为newNode 2.newNode的prev设置为插入位置元素的prev,next设置为插入位置元素 3.插入位置元素的prev设置为newNode succ = node(index);//获取要插入位置的元素 pred = succ.prev; //获取要插入位置元素的prev } //循环添加新节点 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); //把新节点的prev指向队尾 if (pred == null) //队尾为空为空链表,需设置第一个节点 first = newNode; else pred.next = newNode; //把队尾的next指向新节点 pred = newNode; //1)设置新队尾 } if (succ == null) { //1)更新队尾 last = pred; } else { //2) pred.next = succ; //更新队尾为 :插入位置的元素 succ.prev = pred;//更新队尾的prev为newNode } size += numNew; modCount++; return true; }
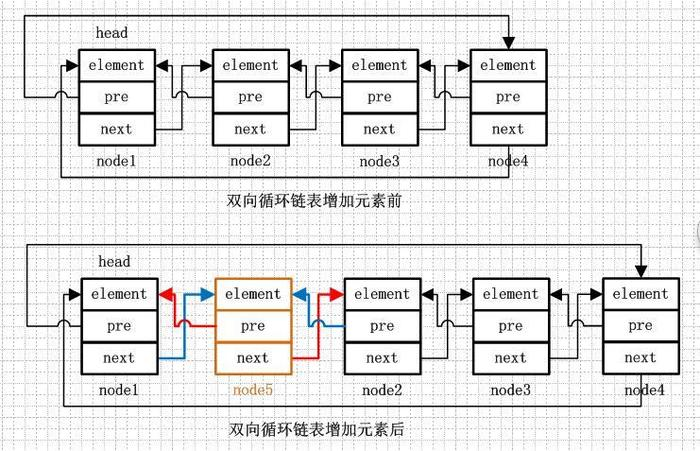
增加方法的代码理解起来可能有些困难,但是只要理解了双向链表的存储结构,掌握增加的核心逻辑就可以了,这里总结一下往链表中增加元素的核心逻辑:1.将元素转换为链表节点,2.增加该节点的前后引用(即pre和next分别指向哪一个节点),3.前后节点对该节点的引用(前节点的next指向该节点,后节点的pre指向该节点)。现在再看下就这么简单么,就是改变前后的互相指向关系 (看图增加元素前后的变化)。??敲里妈的b,代码看完了现在说结论??? 还需要你的马后炮??
其实删除也是一样的对不对?下面看看删除方法的实现。
删除 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 /** * 删除第一个匹配的指定元素 */ public boolean remove(Object o) { // 遍历链表找到要被删除的节点 if (o==null) { for (Entry<E> e = header .next; e != header; e = e.next ) { if (e.element ==null) { remove(e); return true; } } } else { for (Entry<E> e = header .next; e != header; e = e.next ) { if (o.equals(e.element )) { remove(e); return true; } } } return false; } private E remove(Entry<E> e) { if (e == header ) throw new NoSuchElementException(); // 被删除的元素,供返回 E result = e. element; // 下面修正前后对该节点的引用 // 将该节点的上一个节点的next指向该节点的下一个节点 e. previous.next = e.next; // 将该节点的下一个节点的previous指向该节点的上一个节点 e. next.previous = e.previous; // 修正该节点自身的前后引用 e. next = e.previous = null; // 将自身置空,让gc可以尽快回收 e. element = null; // 计数器减一 size--; modCount++; return result; } //下方为 1.8方法: //删除第一个匹配的指定元素 public boolean remove(Object o) { if (o == null) { //从头节点开始遍历,直到遍历到最后一个节点,因为双向链表的最后一个节点的next为null for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } //删除单个节点 E unlink(Node<E> x) { // assert x != null; final E element = x.item; //1 final Node<E> next = x.next; //2 final Node<E> prev = x.prev; //3 if (prev == null) { //删除的为第一个节点 first = next; //首节点设置为删除节点的下一个 } else { prev.next = next; //删除节点的上一个节点next设置为删除节点的下一个节点 x.prev = null; //3)删除节点的上一个节点清空 } if (next == null) {//删除的为尾部 last = prev; //尾部节点设置为删除节点的上一个 } else { next.prev = prev;//删除节点的下个节点的上个节点设置为删除节点的上一个 x.next = null; //2)删除节点的下个节点清空 } x.item = null; //3)删除节点值清空 size--; modCount++; return element; }
上面对于链表增加元素总结了,一句话就是“改变前后的互相指向关系”,删除也是同样的道理,由于节点被删除,该节点的上一个节点和下一个节点互相拉一下小手就可以了,注意的是“互相”,不能一厢情愿。
修改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 /** * 修改指定位置索引位置的元素 */ public E set( int index, E element) { // 查找index位置的节点 Entry<E> e = entry(index); // 取出该节点的元素,供返回使用 E oldVal = e. element; // 用新元素替换旧元素 e. element = element; // 返回旧元素 return oldVal; } //下方为 1.8方法: public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index);// 查找index位置的节点 E oldVal = x.item; // 取出该节点的元素,供返回使用 x.item = element; // 用新元素替换旧元素 return oldVal; }
set方法看起来简单了很多,只要修改该节点上的元素就好了,但是不要忽略了这里的entry()方法,重点就是它。
查询 终于到查询了,终于发现了上面经常出现的那个方法entry()根据index查询节点,我们知道数组是有下标的,通过下标操作天然的支持根据index查询元素,而链表中是没有index概念呢,那么怎么样才能通过index查询到对应的元素呢,下面就来看看LinkedList是怎么实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 /** * 查找指定索引位置的元素 */ public E get( int index) { return entry(index).element ; } //下方为 1.8方法: public E get(int index) { checkElementIndex(index); return node(index).item; } /** * 返回指定索引位置的节点 */ private Entry<E> entry( int index) { // 越界检查 if (index < 0 || index >= size) throw new IndexOutOfBoundsException( "Index: "+index+ ", Size: "+size ); // 取出头结点 Entry<E> e = header; // size>>1右移一位代表除以2,这里使用简单的二分方法,判断index与list的中间位置的距离 if (index < (size >> 1)) { // 如果index距离list中间位置较近,则从头部向后遍历(next) for (int i = 0; i <= index; i++) e = e. next; } else { // 如果index距离list中间位置较远,则从头部向前遍历(previous) for (int i = size; i > index; i--) e = e. previous; } return e; }
???敲里吗的,上面需要entry( int index)你不贴上去,结尾处贴里劳木???基本逻辑懂吗???
现在知道了,LinkedList是通过从header开始index计为0,然后一直往下遍历(next),直到到底index位置。为了优化查询效率,LinkedList采用了二分查找(这里说的二分只是简单的一次二分),判断index与size中间位置的距离,采取从header向后还是向前查找。
到这里我们明白,基于双向循环链表实现的LinkedList,通过索引Index的操作时低效的,index所对应的元素越靠近中间所费时间越长。而向链表两端插入和删除元素则是非常高效的(如果不是两端的话,都需要对链表进行遍历查找)。
是否包含 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 // 判断LinkedList是否包含元素(o) public boolean contains(Object o) { return indexOf(o) != -1; } // 从前向后查找,返回“值为对象(o)的节点对应的索引” // 不存在就返回-1 public int indexOf(Object o) { int index = 0; if (o==null) { for (Entry e = header .next; e != header; e = e.next ) { if (e.element ==null) return index; index++; } } else { for (Entry e = header .next; e != header; e = e.next ) { if (o.equals(e.element )) return index; index++; } } return -1; } // 从后向前查找,返回“值为对象(o)的节点对应的索引” // 不存在就返回-1 public int lastIndexOf(Object o) { int index = size ; if (o==null) { for (Entry e = header .previous; e != header; e = e.previous ) { index--; if (e.element ==null) return index; } } else { for (Entry e = header .previous; e != header; e = e.previous ) { index--; if (o.equals(e.element )) return index; } } return -1; } //下方为 1.8方法: public int indexOf(Object o) { // 从前向后查找,返回“值为对象(o)的节点对应的索引” int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; } public int lastIndexOf(Object o) {// 从后向前查找,返回“值为对象(o)的节点对应的索引” int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; }
和public boolean remove(Object o) 一样,indexOf查询元素位于容器的索引位置,都是需要对链表进行遍历操作,当然也就是低效了啦。
判断容量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 /** * Returns the number of elements in this list. * * @return the number of elements in this list */ public int size() { return size ; } /** * {@inheritDoc} * * <p>This implementation returns <tt>size() == 0 </tt>. */ public boolean isEmpty() { return size() == 0; }
和ArrayList一样,基于计数器size操作,容量判断很方便。
到这里LinkedList就分析完了,不对好像还差些什么对不对?是什么呢,就是最开始说的Deque双端队列,明白了链表原理和LinkedList的基本crud操作,Deque的LinkedList实现就已经是so easy了,我们简单看下。
LinkedList实现的Deque双端队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 /** * Adds the specified element as the tail (last element) of this list. * * @param e the element to add * @return <tt> true</tt> (as specified by {@link Queue#offer}) * @since 1.5 */ public boolean offer(E e) { //1)尾部添加 return add(e); } /** * Retrieves and removes the head (first element) of this list * @return the head of this list, or <tt>null </tt> if this list is empty * @since 1.5 */ public E poll() { //2)移除首节点 if (size ==0) return null; return removeFirst(); } /** * Removes and returns the first element from this list. * * @return the first element from this list * @throws NoSuchElementException if this list is empty */ public E removeFirst() { return remove(header .next); } /** * Retrieves, but does not remove, the head (first element) of this list. * @return the head of this list, or <tt>null </tt> if this list is empty * @since 1.5 */ public E peek() { //3)获取首节点 if (size ==0) return null; return getFirst(); } /** * Returns the first element in this list. * * @return the first element in this list * @throws NoSuchElementException if this list is empty */ public E getFirst() { if (size ==0) throw new NoSuchElementException(); return header .next. element; } /** * Pushes an element onto the stack represented by this list. In other * words, inserts the element at the front of this list. * * <p>This method is equivalent to {@link #addFirst}. * * @param e the element to push * @since 1.6 */ public void push(E e) {//4)新增首节点 addFirst(e); } /** * Inserts the specified element at the beginning of this list. * * @param e the element to add */ public void addFirst(E e) { addBefore(e, header.next ); }
看看Deque 的实现是不是很简单,逻辑都是基于上面讲的链表操作的,对于队列的一些概念我不打算在这里讲,是因为后面队列会单独拿出来分析啦,这里只要理解基于链表实现的list内部是怎么操作的就可以啦。
总结 :
(01) LinkedList 实际上是通过双向链表去实现的。
它包含一个非常重要的内部类:Entry 。Entry是双向链表节点所对应的数据结构 ,它包括的属性有:当前节点所包含的值 ,上一个节点 ,下一个节点 。
(02) 从LinkedList的实现方式中可以发现,它不存在LinkedList容量不足的问题。
(03) LinkedList的克隆函数,即是将全部元素克隆到一个新的LinkedList对象中。
(04) LinkedList实现java.io.Serializable。当写入到输出流时,先写入“容量”,再依次写入“每一个节点保护的值”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
(05) 由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。
对LinkedList以及ArrayList的迭代效率比较 先说结论:ArrayList使用最普通的for循环遍历比较快,LinkedList使用foreach循环比较快。
看一下两个List的定义:
1 2 public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
1 2 3 public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
注意到ArrayList是实现了RandomAccess接口而LinkedList则没有实现这个接口,关于RandomAccess这个接口的作用,看一下JDK API上的说法:
为此,我写一段代码证明一下这一点,注意,虽然上面的例子用的Iterator,但是做foreach循环的时候,编译器默认会使用这个集合的Iterator。测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class TestMain { private static int SIZE = 111111; private static void loopList(List<Integer> list) { long startTime = System.currentTimeMillis(); for (int i = 0; i < list.size(); i++) { list.get(i); } System.out.println(list.getClass().getSimpleName() + "使用普通for循环遍历时间为" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); for (Integer i : list) { } System.out.println(list.getClass().getSimpleName() + "使用foreach循环遍历时间为" + (System.currentTimeMillis() - startTime) + "ms"); } public static void main(String[] args) { List<Integer> arrayList = new ArrayList<Integer>(SIZE); List<Integer> linkedList = new LinkedList<Integer>(); for (int i = 0; i < SIZE; i++) { arrayList.add(i); linkedList.add(i); } loopList(arrayList); loopList(linkedList); System.out.println(); } }
我截取三次运行结果:
1 2 3 4 ArrayList使用普通for循环遍历时间为10ms ArrayList使用foreach循环遍历时间为36ms LinkedList使用普通for循环遍历时间为21841ms LinkedList使用foreach循环遍历时间为34ms
1 2 3 4 ArrayList使用普通for循环遍历时间为11ms ArrayList使用foreach循环遍历时间为27ms LinkedList使用普通for循环遍历时间为20500ms LinkedList使用foreach循环遍历时间为27ms
1 2 3 4 ArrayList使用普通for循环遍历时间为10ms ArrayList使用foreach循环遍历时间为22ms LinkedList使用普通for循环遍历时间为20237ms LinkedList使用foreach循环遍历时间为38ms
有了JDK API的解释,这个结果并不让人感到意外,最最想要提出的一点是:如果使用普通for循环遍历LinkedList,其遍历速度将慢得令人发指。
总结 ArrayList和LinkedList的比较 1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
2、基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
3、数据遍历的速度,看最后一部分,这里就不细讲了,结论是:使用各自遍历效率最高的方式,ArrayList的遍历效率会比LinkedList的遍历效率高一些
4、有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList 。
从这个分析看出,如果你十分确定你插入、删除的元素是在前半段,那么就使用LinkedList;如果你十分确定你删除、删除的元素在比较靠后的位置,那么可以考虑使用ArrayList。如果你不能确定你要做的插入、删除是在哪儿呢?那还是建议你使用LinkedList吧,因为一来LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;二来插入元素的时候,弄得不好ArrayList就要进行一次扩容,记住,ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作 。
参考 该文为本人学习的笔记,方便以后自己跳槽前复习。参考网上各大帖子,取其精华整合自己的理解而成。集合框架源码面试经常会问,所以解读源码十分必要,希望对你有用。
队列: http://blog.csdn.net/l540675759/article/details/62893335
Java集合类框架学习 3 —— LinkedList(JDK1.8/JDK1.7/JDK1.6)http://blog.csdn.net/u011392897/article/details/57115818
java提高篇(二三)—–HashMap
Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
图解集合4:HashMap
整理的集合框架思维导图
原文链接:http://www.jianshu.com/p/d5ec2ff72b33