
1-架构原理
架构原理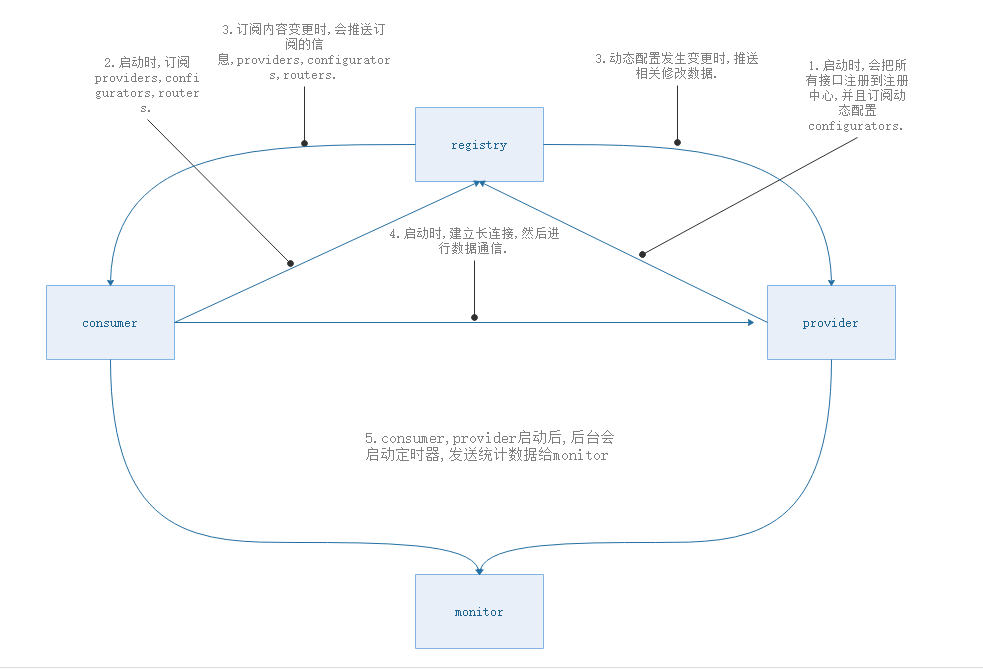
注册节点属性:
ls /dubbo/包名+类名/ [consumers, configurators, routers, providers]
consumers+providers 属性分隔:%+2位特定规则的值(获取时解析成系统中对应符号)
[dubbo%3A%2F%2F192.168.174.1%3A20880%2Fcom.alibaba.dubbo.demo.DemoService%3Fanyhost%3Dtrue%26application%3Ddemo-provider%26dubbo%3D2.0.0%26generic%3Dfalse%26interface%3Dcom.alibaba.dubbo.demo.DemoService%26loadbalance%3Droundrobin%26methods%3DsayHello%26owner%3Dwilliam%26pid%3D6328%26side%3Dprovider%26timestamp%3D1514174041367]
[consumer%3A%2F%2F192.168.174.1%2Fcom.alibaba.dubbo.demo.DemoService%3Fapplication%3Ddemo-consumer%26category%3Dconsumers%26check%3Dfalse%26dubbo%3D2.0.0%26interface%3Dcom.alibaba.dubbo.demo.DemoService%26methods%3DsayHello%26pid%3D16672%26side%3Dconsumer%26timestamp%3D1514175571507]
provider启动: 创建节点:providers、configurators
consumer启动:创建节点:consumers, configurators, routers, providers (provider未启动 则节点providers为[])
consumers+providers:
1.主机地址+端口号
2.包名+类名
3.methods:类中的全部方法名
4.loadbalance :负载均衡策略(providers)
5.timestamp :时间戳
6.provider或consumer的标识
7.pid:注册方的进程名
8.anyhost:任何主机都能连(providers)
9.dubbo.application.name :服务标识名
10.节点中没有方法参数
2-dubbo自己的SPI实现
dubbo自己的SPI实现-1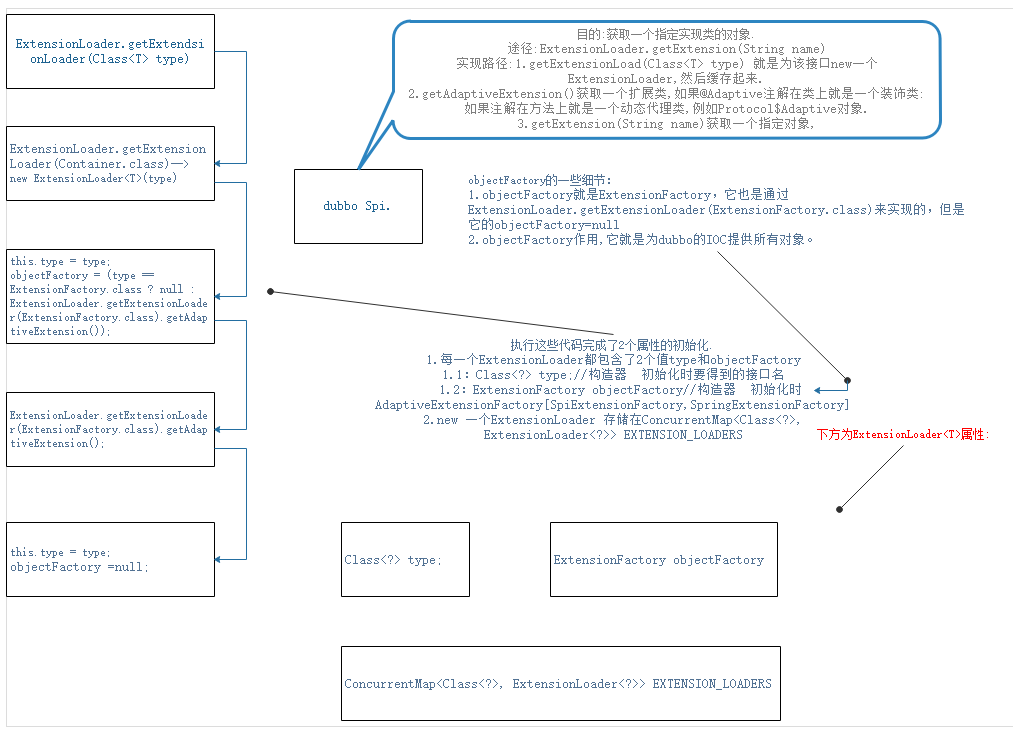
extension_loaders:只缓存dubbo内置的22~23个类
/**
*spi的设计目标:
*面向的对象的设计里,模块之间是基于接口编程,模块之间不对实现类进行硬编码。
*一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。
*为了实现在模块装配的时候,不在模块里面写死代码,这就需要一种服务发现机制。
*java spi就是提供这样的一个机制:
*为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到代码之外。
*
*
*spi的具体约定如下 :
*当服务的提供者(provider),提供了一个接口多种实现时,
*一般会在jar包的META-INF/services/目录下,创建该接口的同名文件。
*该文件里面的内容就是该服务接口的具体实现类的名称。
*而当外部加载这个模块的时候,
*就能通过该jar包META-INF/services/里的配置文件得到具体的实现类名,并加载实例化,完成模块的装配。
*/
dubbo自己的SPI实现-2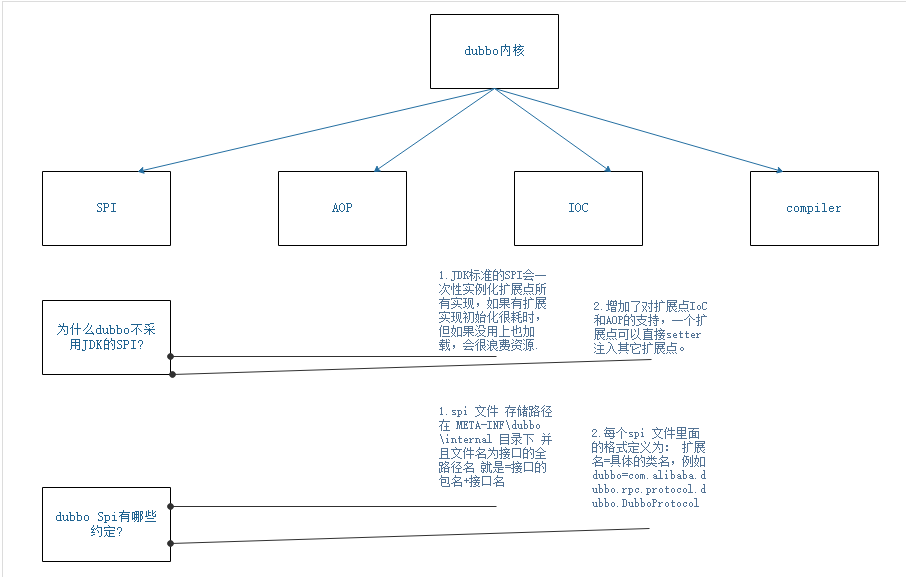
3-SPI机制的adaptive原理
SPI机制的adaptive原理-1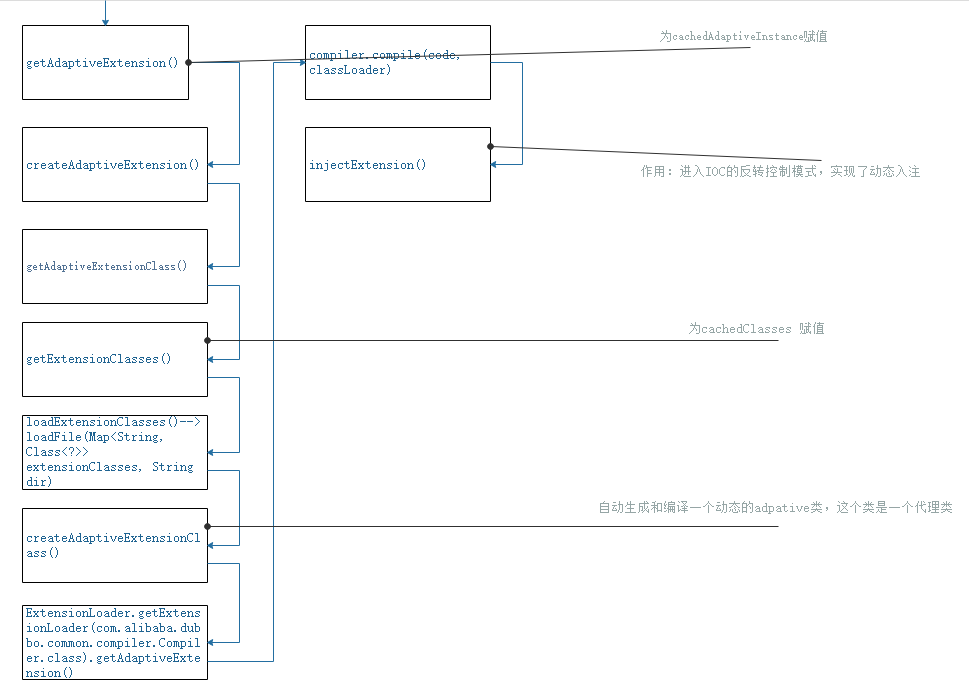
SPI机制的adaptive原理-2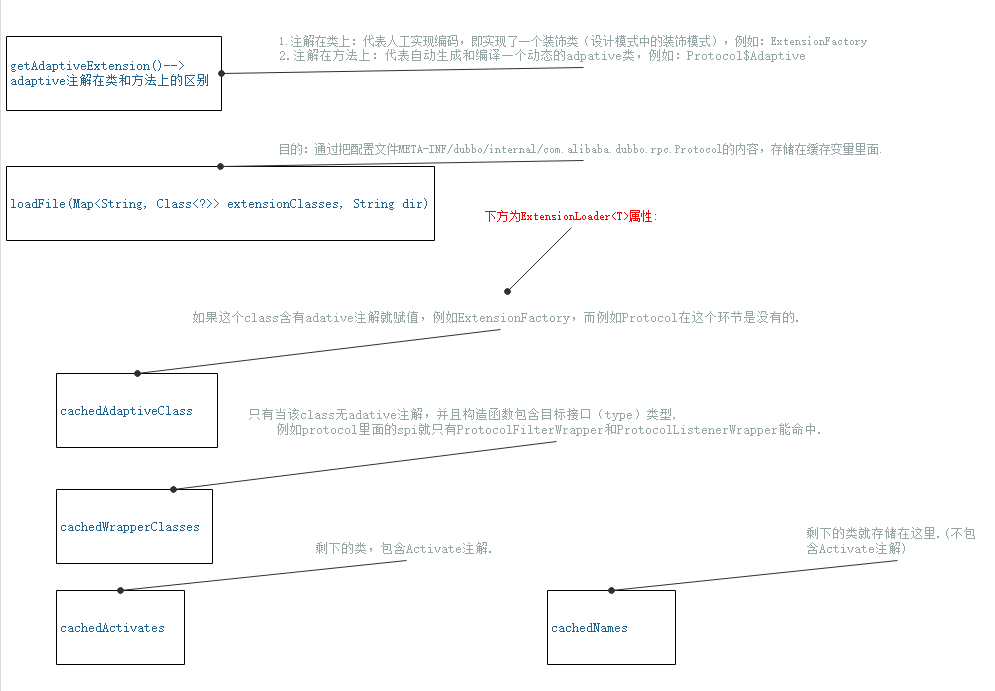
loadFile方法 :
1.会加载ExtensionLoader子项目中配置的 :1.META-INF/dubbo/internal/ 2.META-INF/dubbo/ 3.META-INF/services/ 下配置的spi
- StringfileName = dir +type.getName(); 获取一个当前type接口(包名+类名)的spi文件名
3.Enumeration<java.net.URL> urls = classLoader.getResources(fileName); || = ClassLoader.getSystemResources(fileName);
java.net.URLurl= urls.nextElement(); //url为绝对路径
通过: BufferedReaderreader =newBufferedReader(newInputStreamReader(url.openStream(),”utf-8”));
4-dubbo自己的IOC和AOP原理
dubbo自己的IOC和AOP原理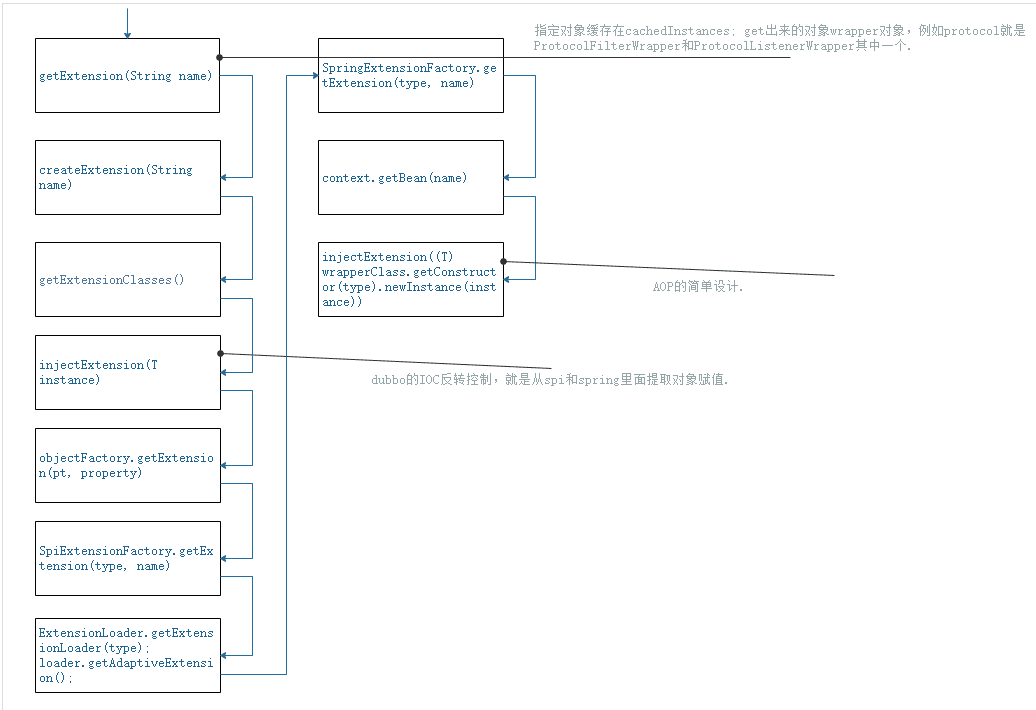
ioc
1.ioc反转控制:SpiExtensionFactory SpringExtensionFactory(bean名称为spring默认的名称)
method.invoke(instance,object); 获取的都是setter方法,获取值则赋予。
2.AOP:获取ioc里对象时,调用了injectExtension方法前,使用通知wrapperClass包装创建了type。
5-dubbo的动态编译原理
dubbo的动态编译原理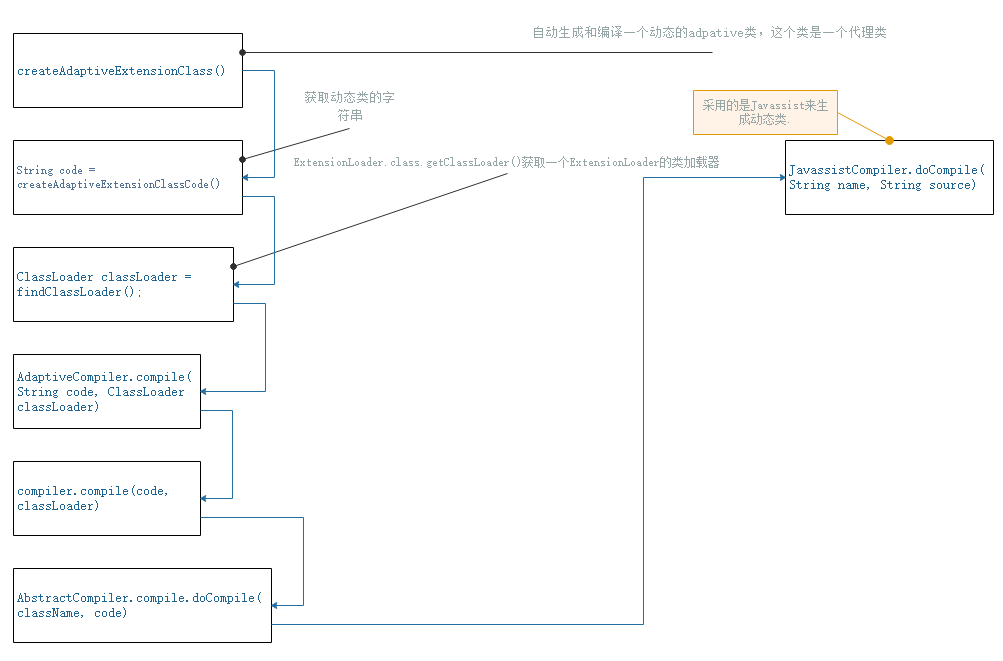
1.使用的StringBuilder.append();构造的动态字符串。
6-dubbo如何和spring完美融合
dubbo如何和spring完美融合-1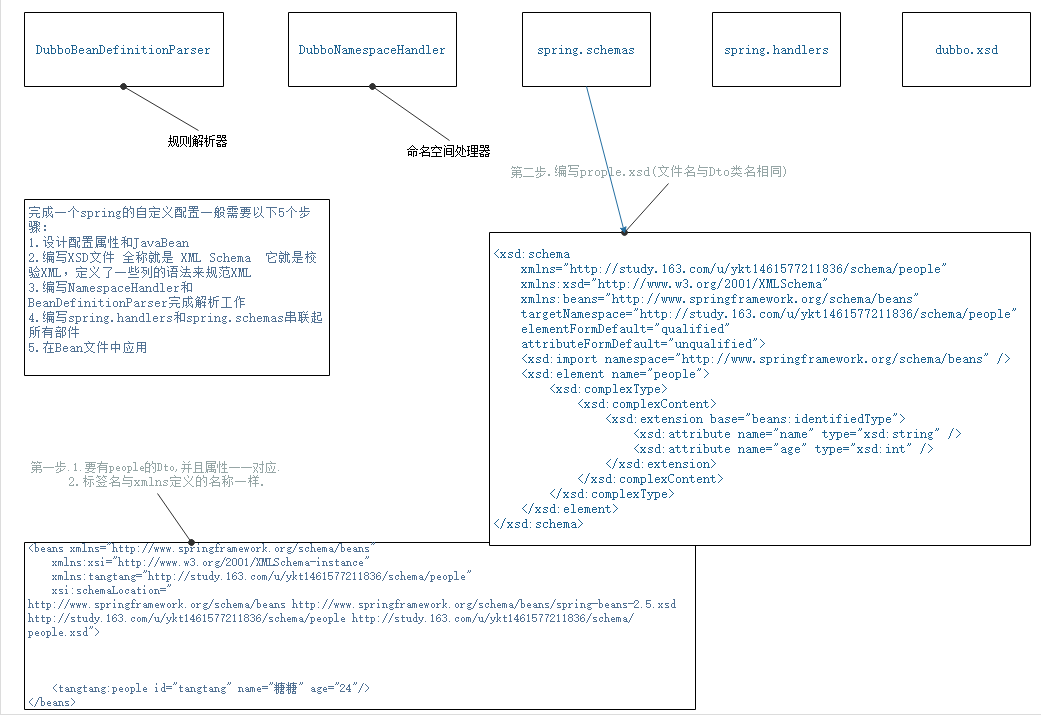
dubbo如何和spring完美融合-2
dubbo如何和spring完美融合-3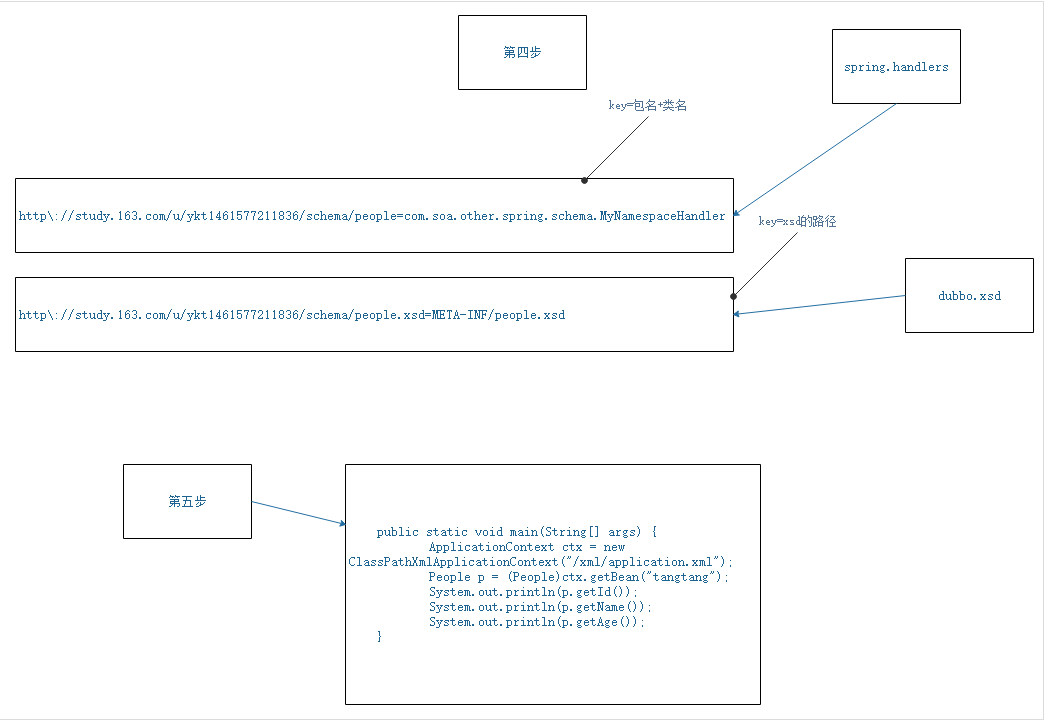
解析xml:org.w3c.dom
7-服务发布的原理探索
服务发布的原理探索-1
服务发布的原理探索-2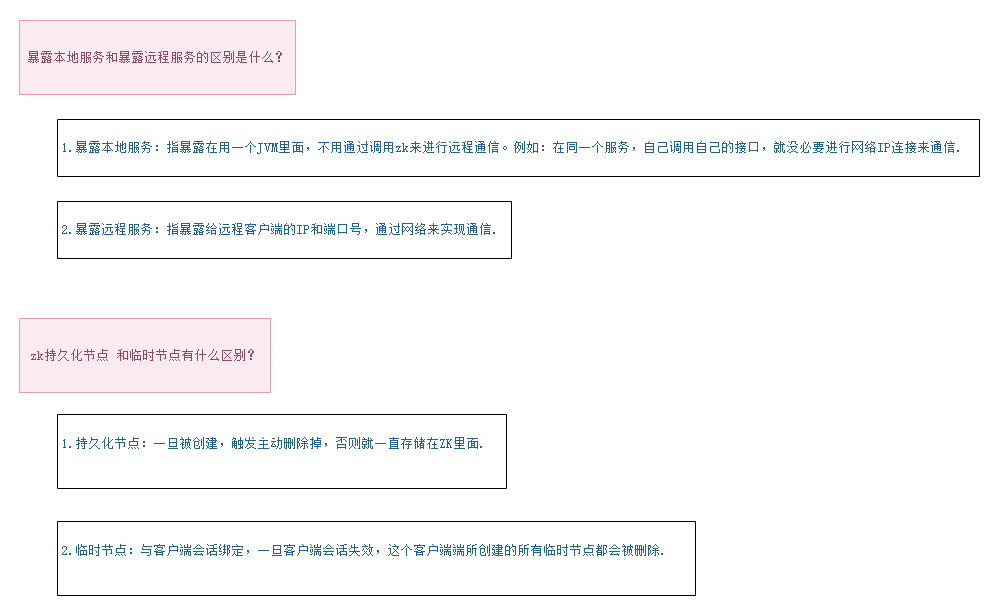
服务发布的原理探索-3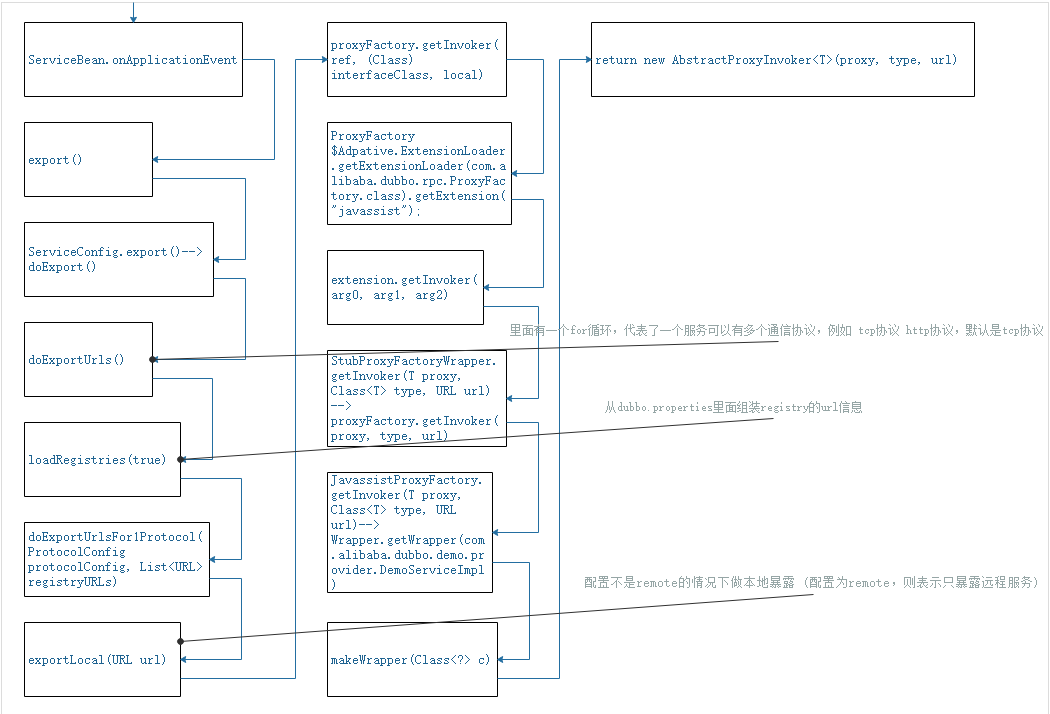
服务发布的原理探索-4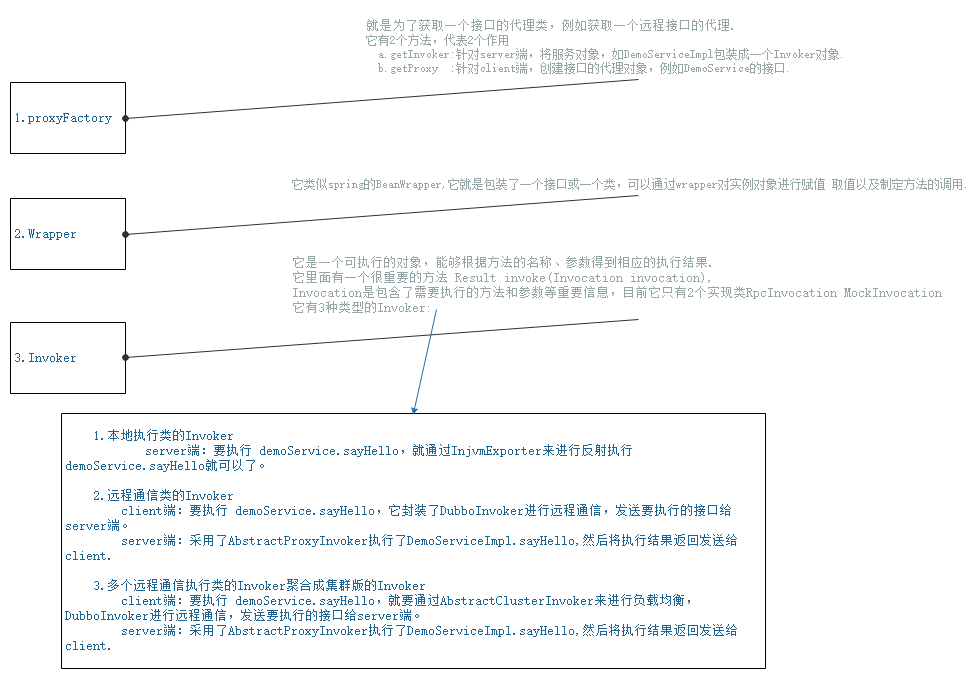
8-netty的服务暴露
netty的服务暴露-1 本地暴露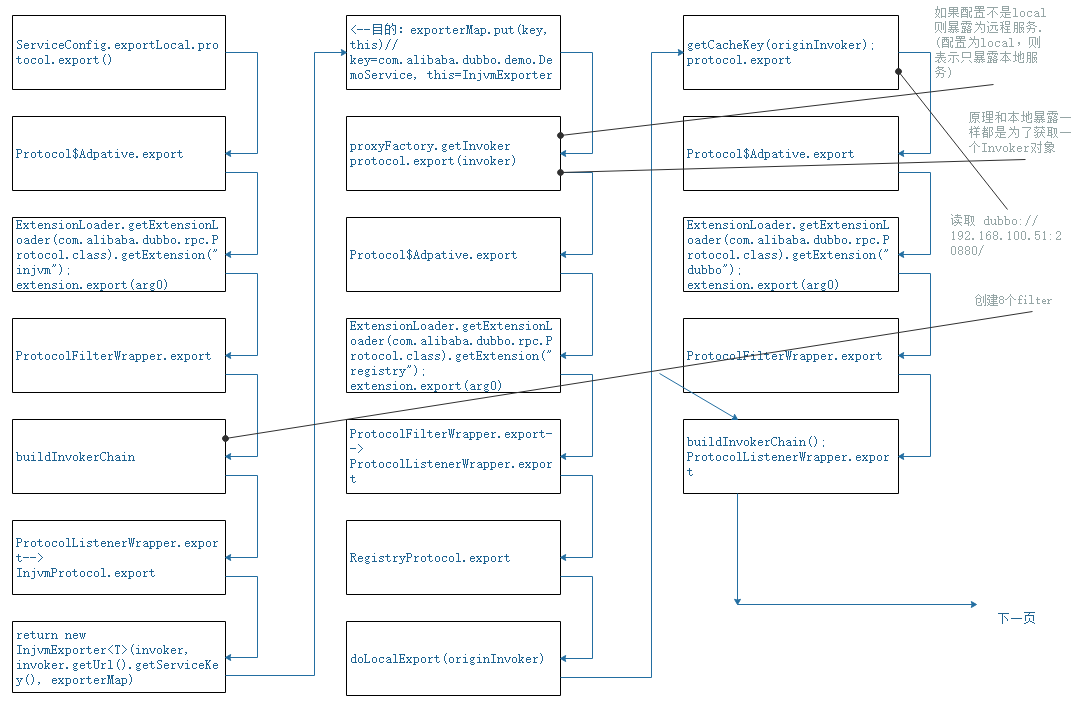
netty的服务暴露-2 网络暴露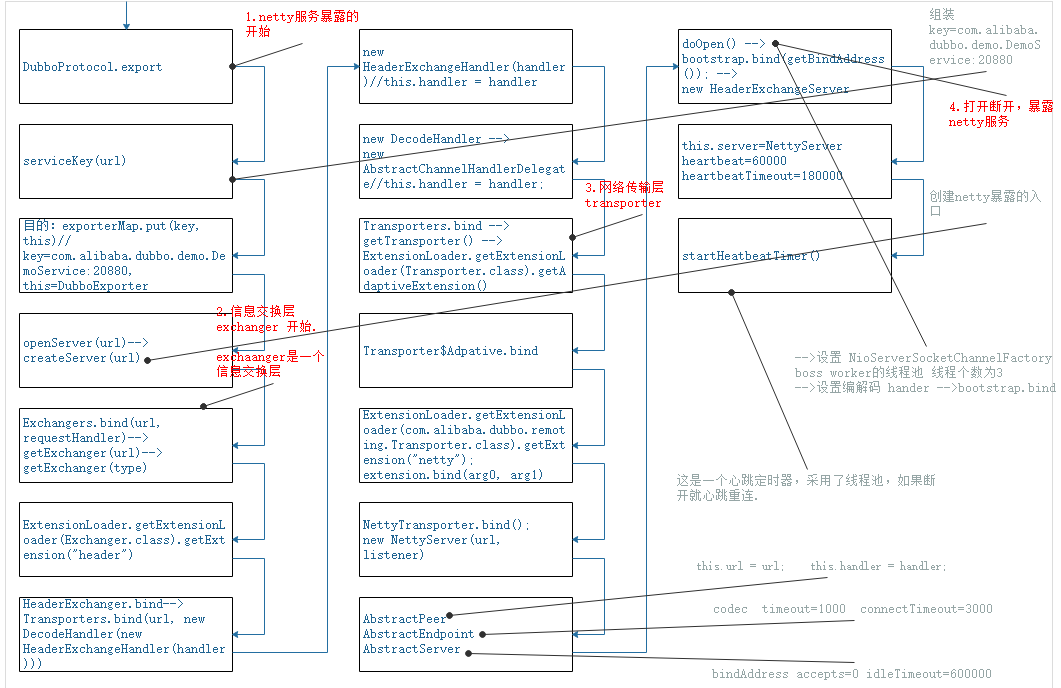
ScheduledExecutorServices cheduled; 线程池
scheduled.scheduleWithFixedDelay
线程池
command:执行线程
initialDelay:初始化延时 默认60000
period:前一次执行结束到下一次执行开始的间隔时间(间隔执行延迟时间) 默认60000
unit:计时单位 TimeUnit.MILLISECONDS
默认1个线程
9-zookeeper的连接-创建-订阅
zookeeper的连接-创建-订阅
10-dubbo如何连接zookeeper
dubbo如何连接zookeeper
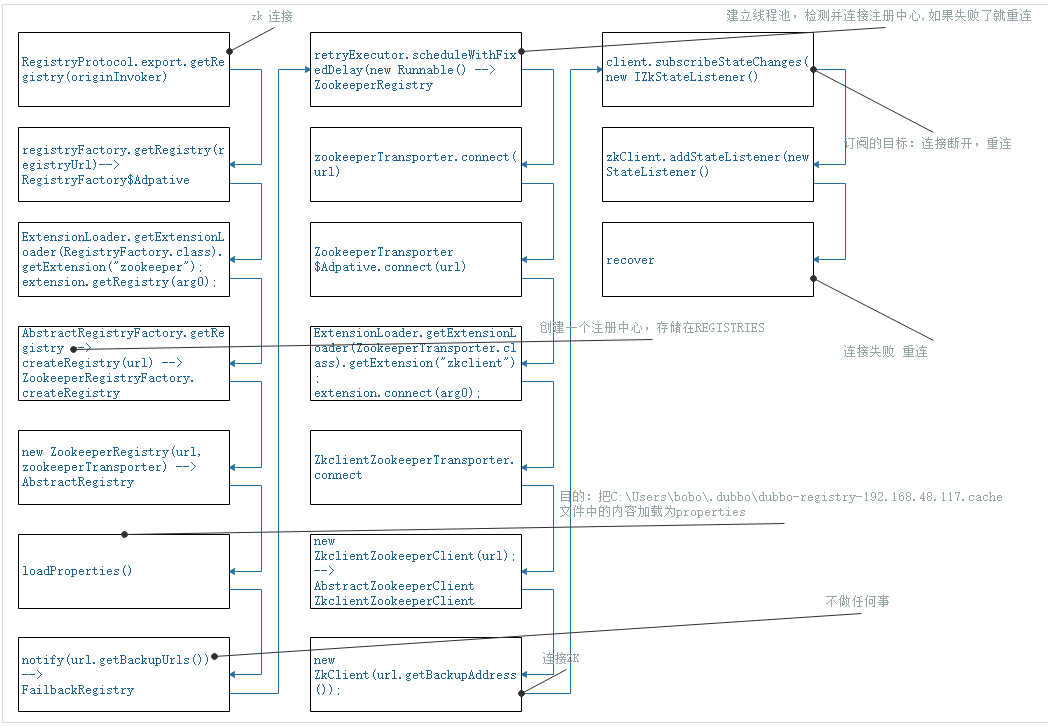
线程池
线程池
command:执行线程
initialDelay:初始化延时 默认5000
period:前一次执行结束到下一次执行开始的间隔时间(间隔执行延迟时间) 默认5000
unit:计时单位 TimeUnit.MILLISECONDS
默认1个线程
11-dubbo如何创建zookeeper节点
dubbo如何创建zookeeper节点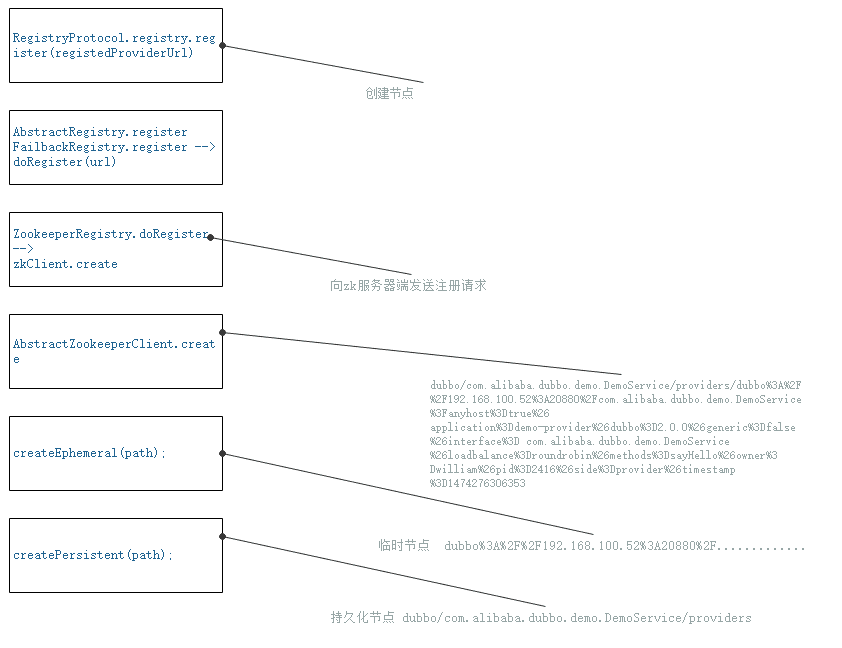
除了最后一层节点 都是持久化节点
12-dubbo如何订阅zookeeper信息
dubbo如何订阅zookeeper信息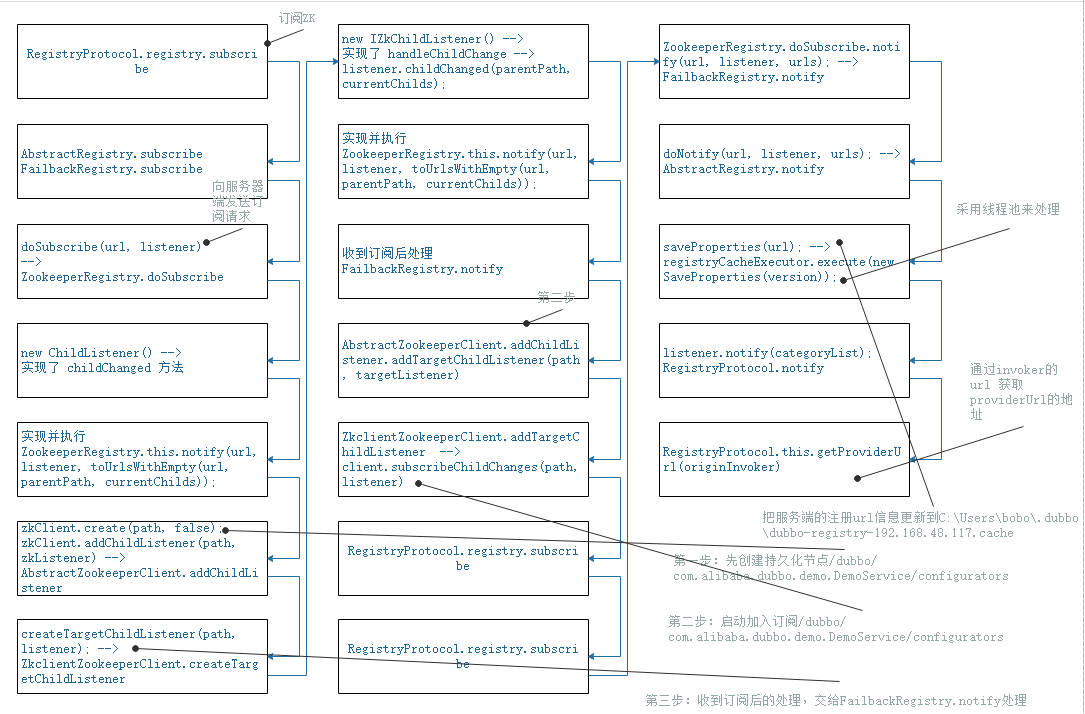
13-服务发布–整体架构设计图
服务发布–整体架构设计图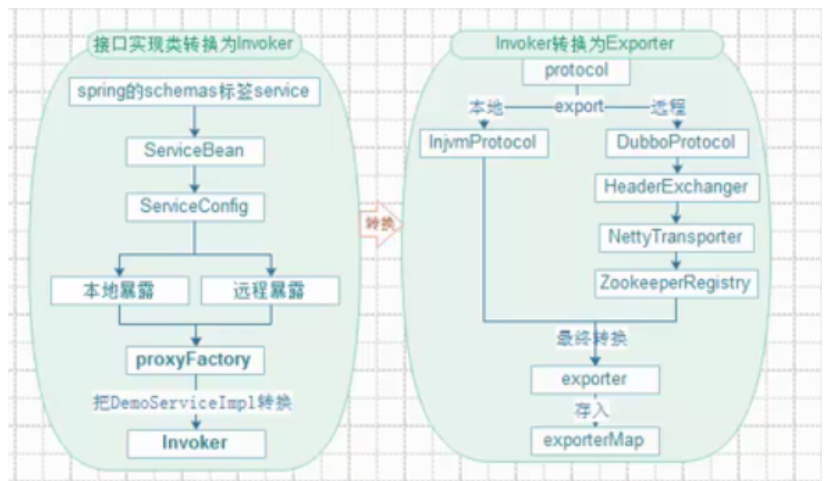
exporterMap : key:包名+类名 : 端口号
14-服务引用的设计原理
服务引用的设计原理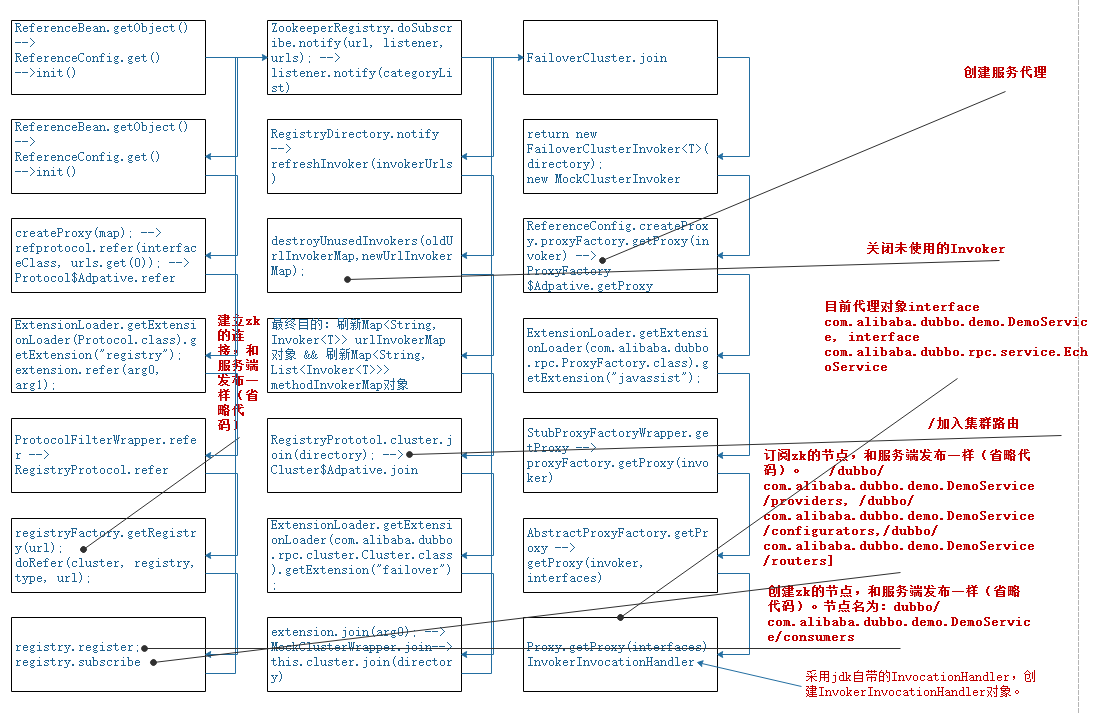
methodInvokerMap
providerUrl : zk中的providers节点值
invoker 与 url :zk中的consumers节点值
urlInvokerMap
providerUrl : zk中的providers节点值
key 、invoker 与 url :zk中的consumers节点值
15-服务引用–整体架构设计图
服务引用–整体架构设计图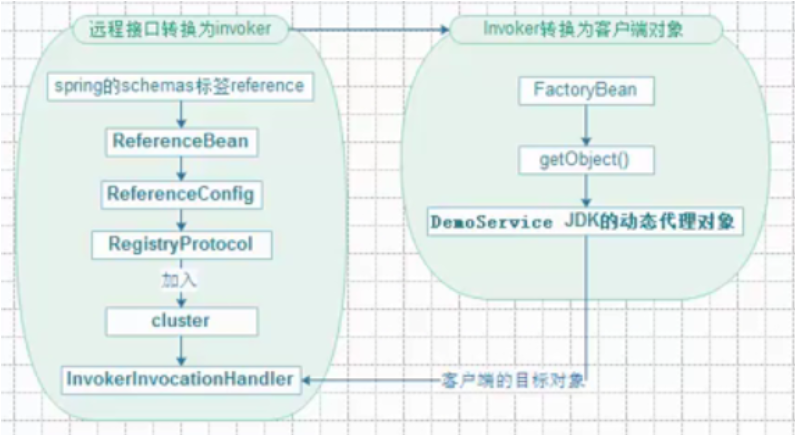
16-集群容错之架构设计解剖
集群容错之架构设计解剖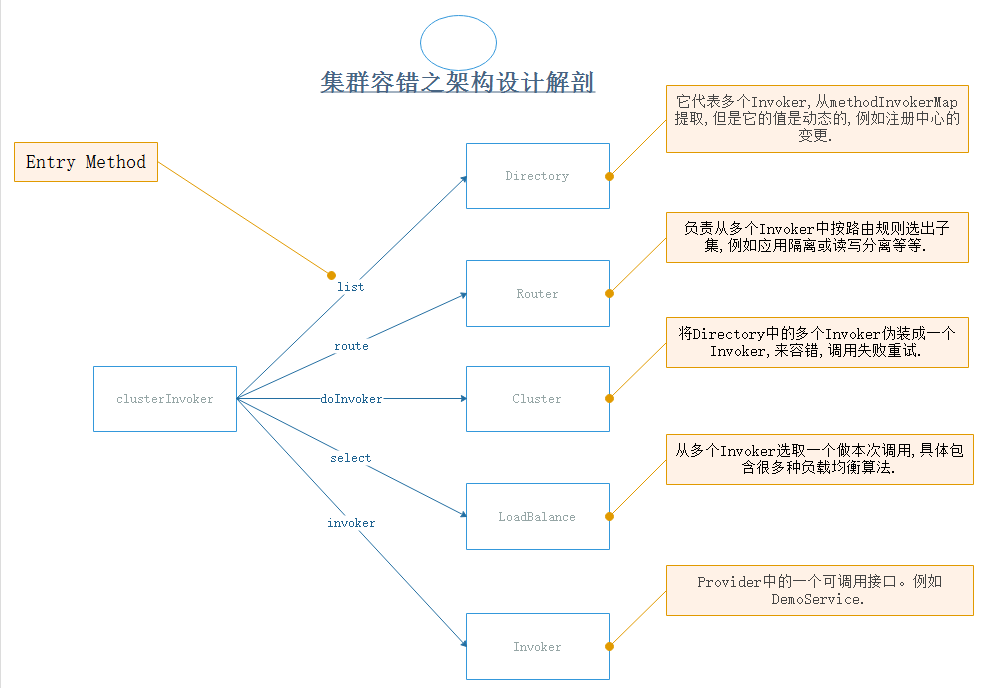
17-容错集群之directory目录
容错集群之directory目录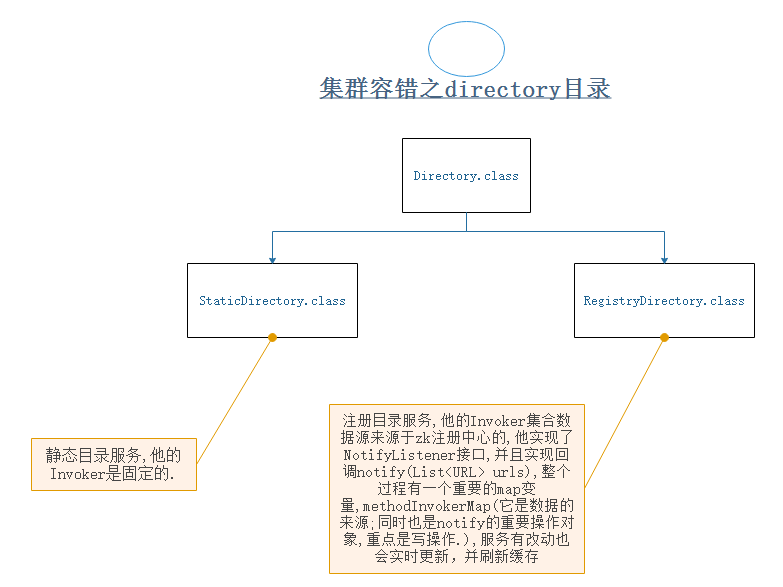
18-容错集群之router路由规则
容错集群之router路由规则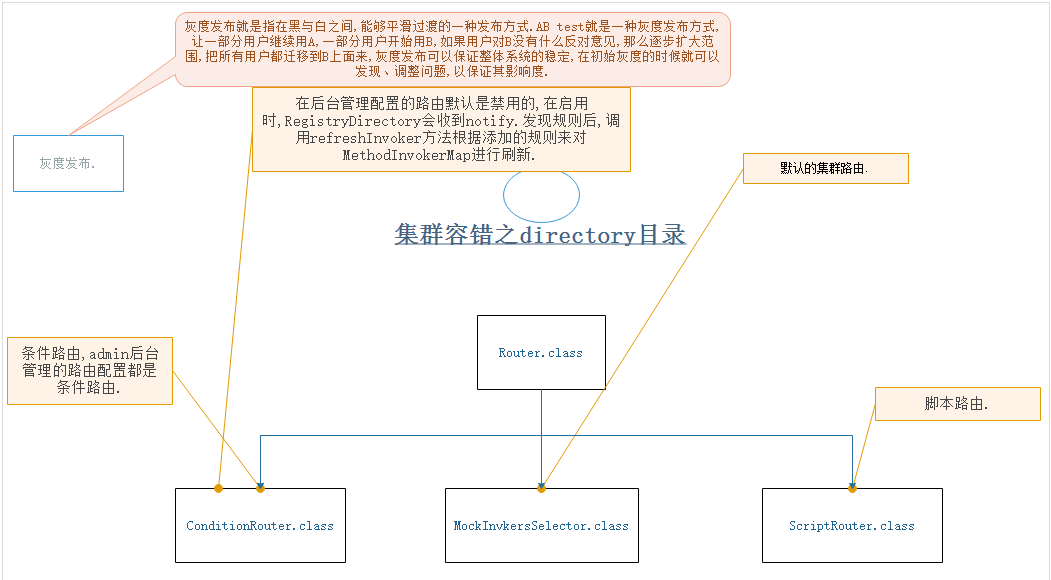
19-集群容错之cluster集群
集群容错之cluster集群-1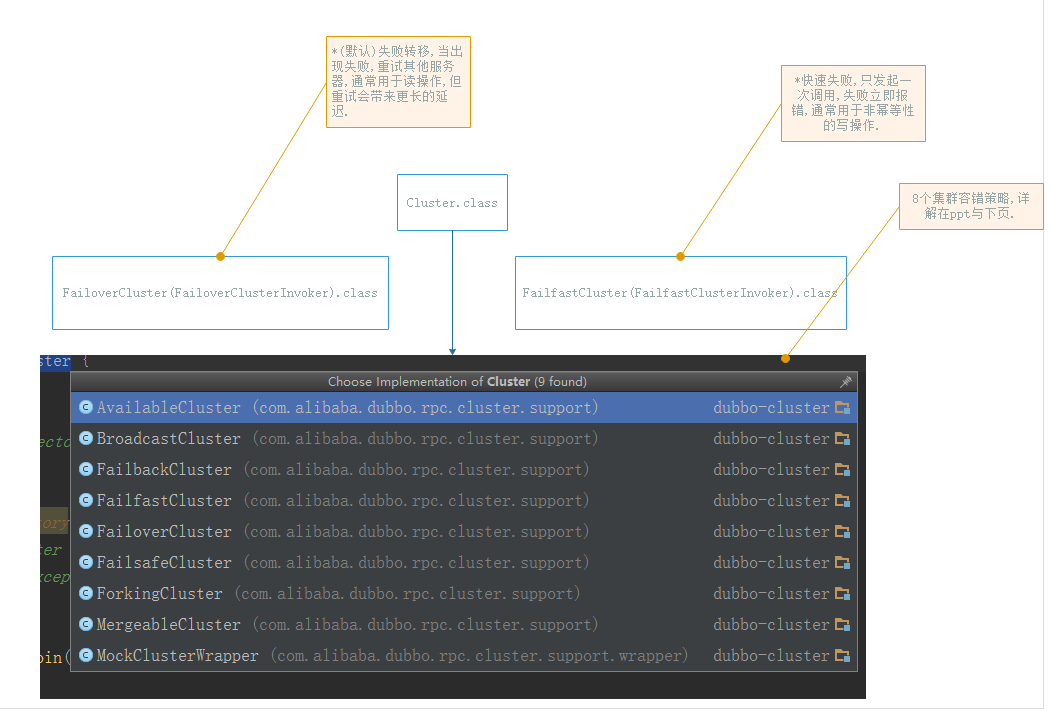
集群容错之cluster集群-2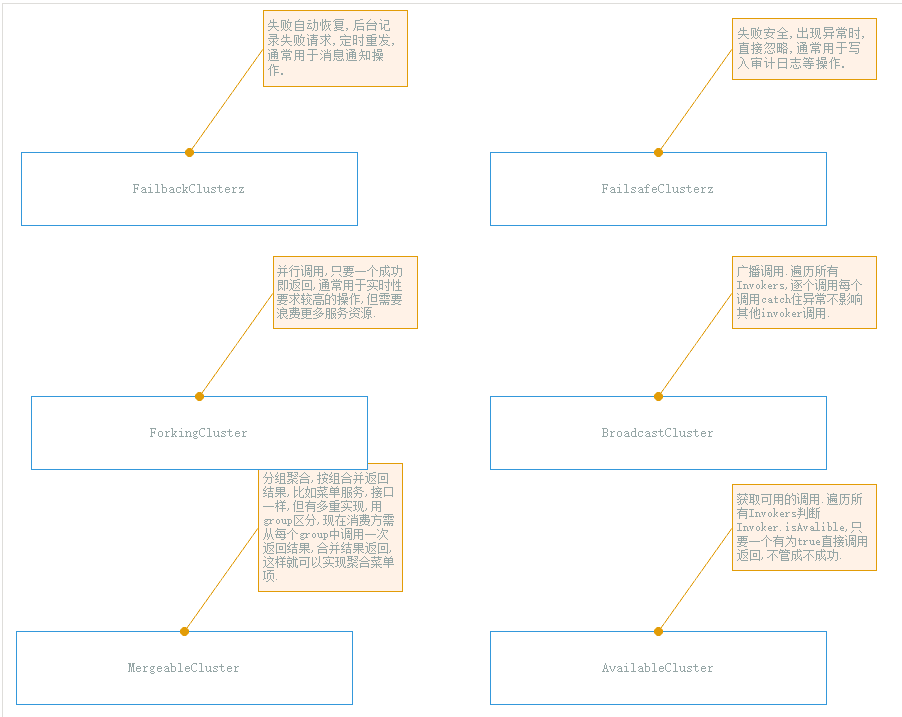
20-容错集群之loadbalance负载均衡
容错集群之loadbalance负载均衡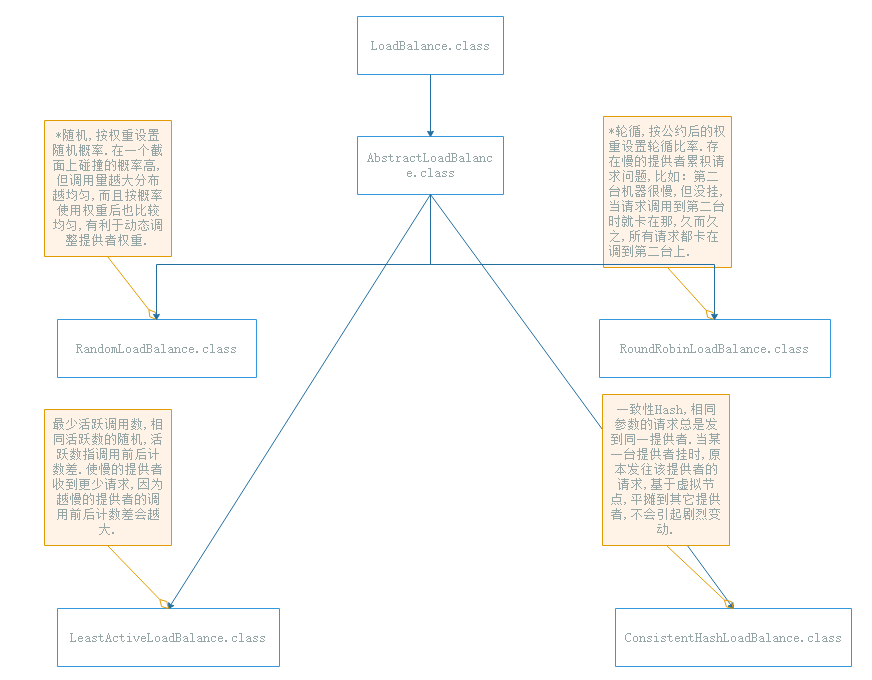
21-dubbo如何实现SOA的服务降级
dubbo如何实现SOA的服务降级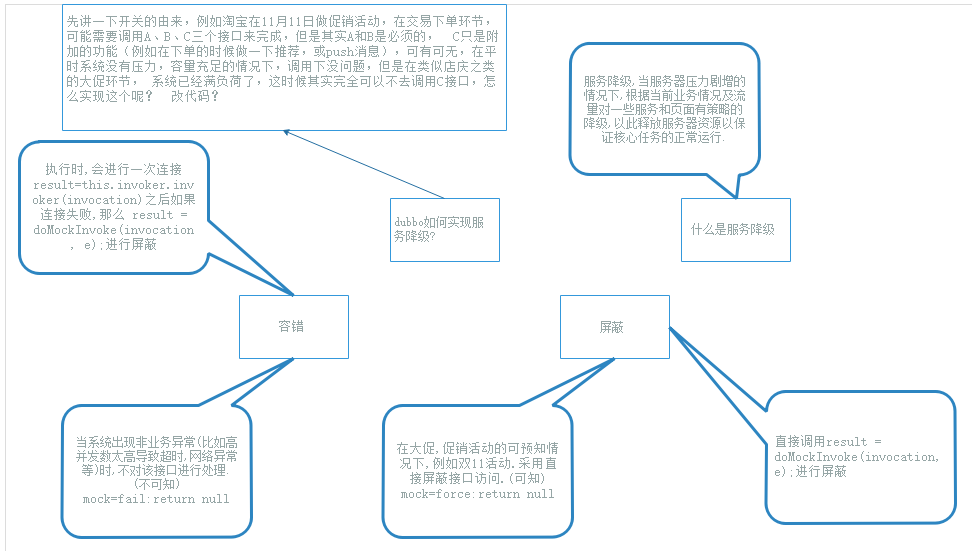
22-网络通信-consumer发送原理
网络通信-consumer发送原理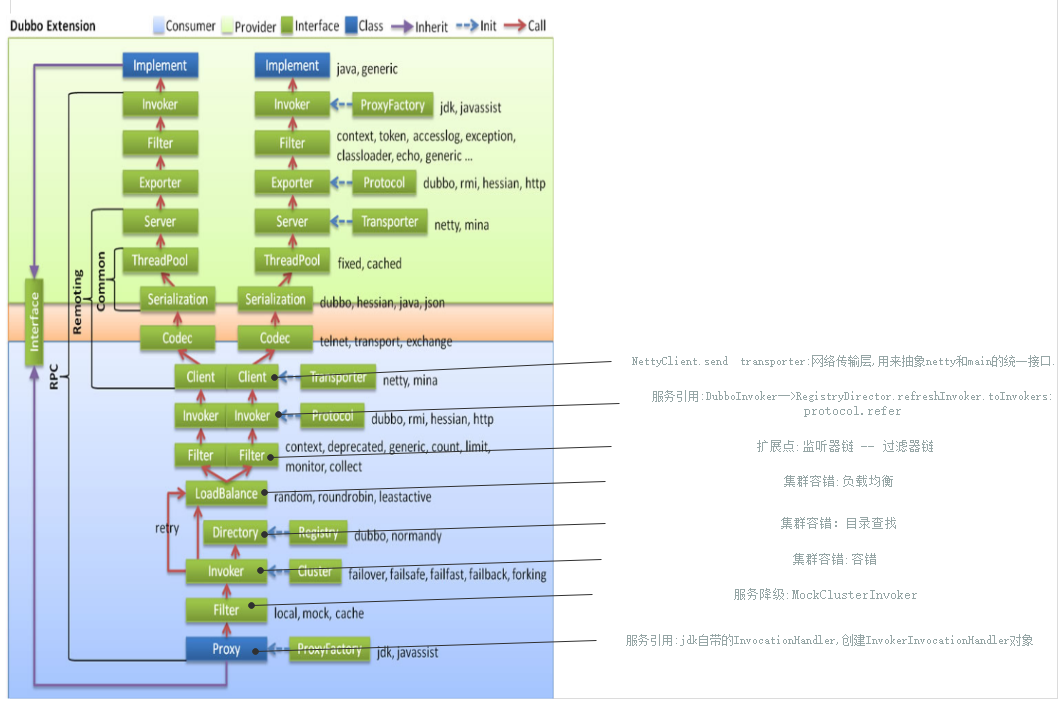
23-网络通信-provider的接收与发送原理
网络通信-provider的接收与发送原理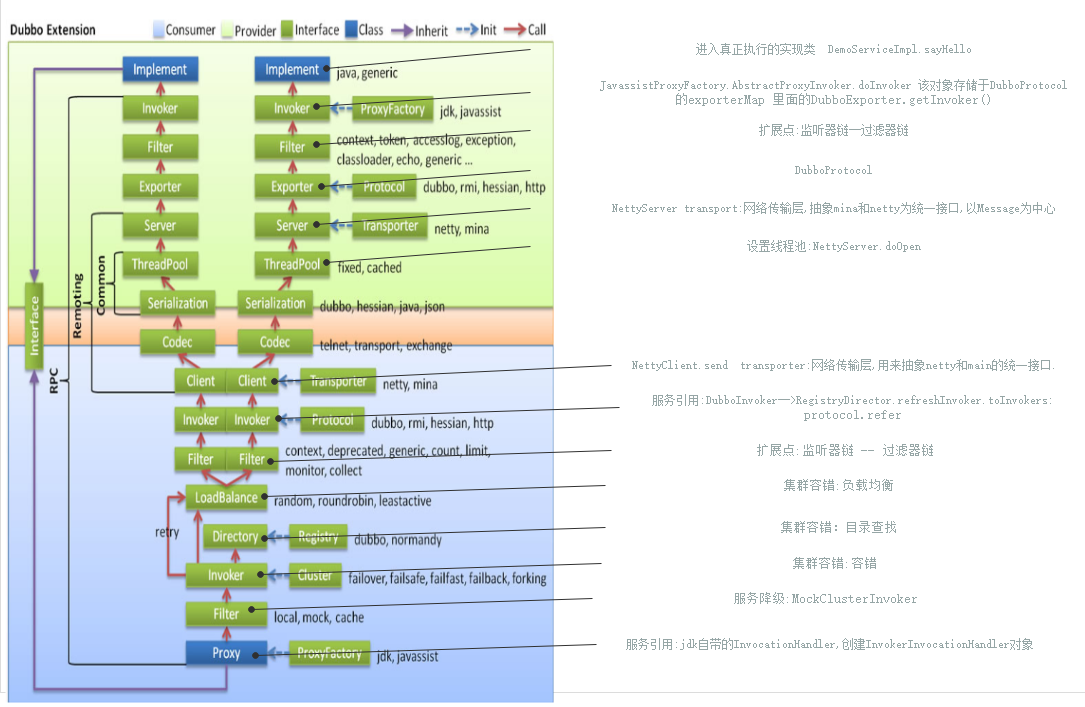
24-网络通信-consumer的接收原理
网络通信-consumer的接收原理
25-单工、全双工、半双工区别
单工、全双工、半双工区别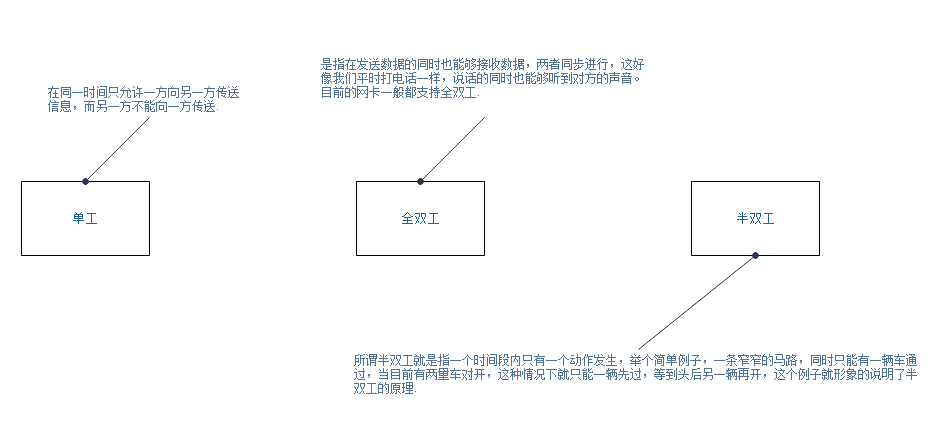
26-dubbo的核心级概念-invoker总结
dubbo的核心级概念-invoker总结-1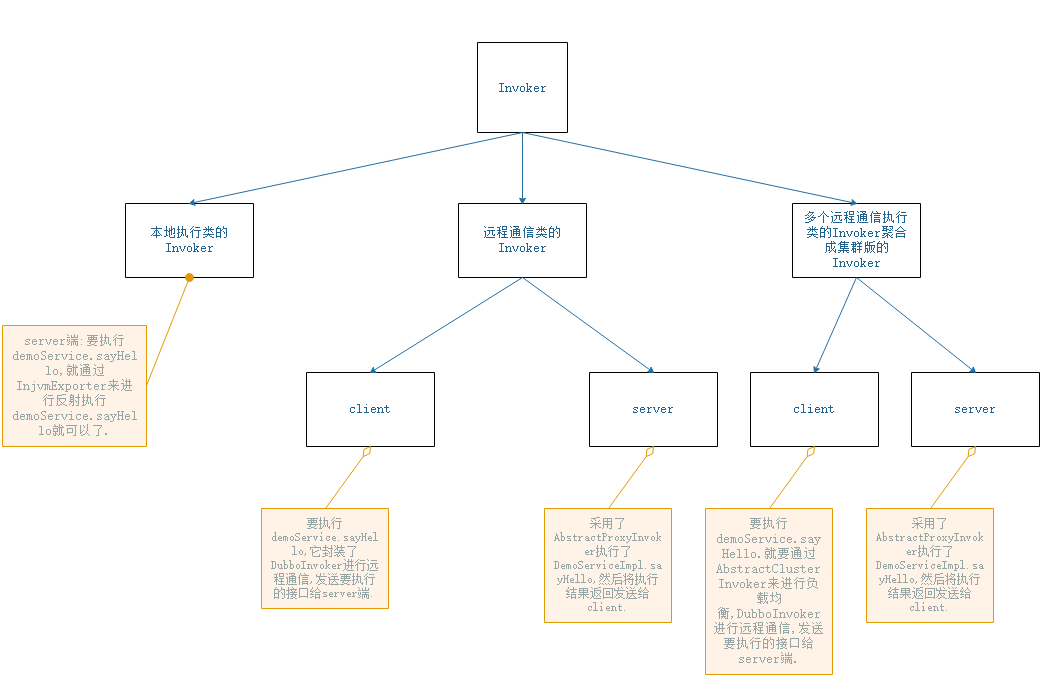
dubbo的核心级概念-invoker总结-2
27-网络通信–编码解码之consumer请求编码
网络通信–编码解码之consumer请求编码 -1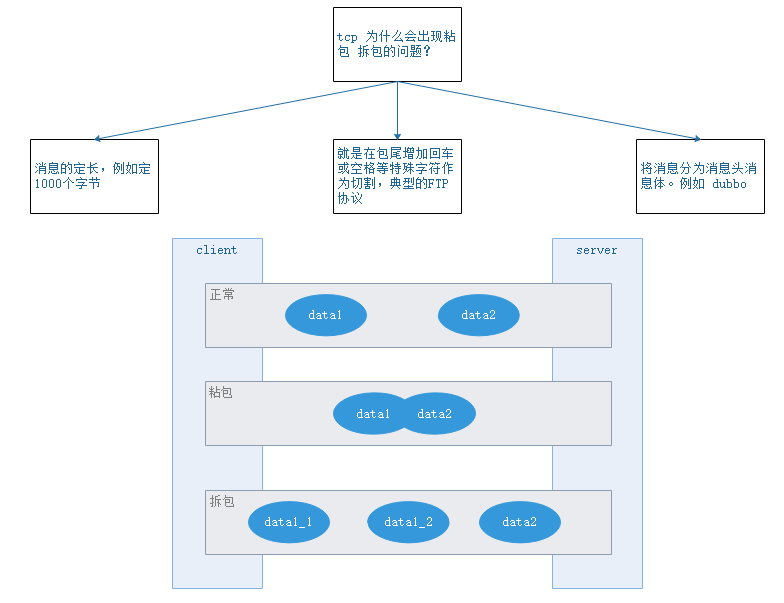
网络通信–编码解码之consumer请求编码 -2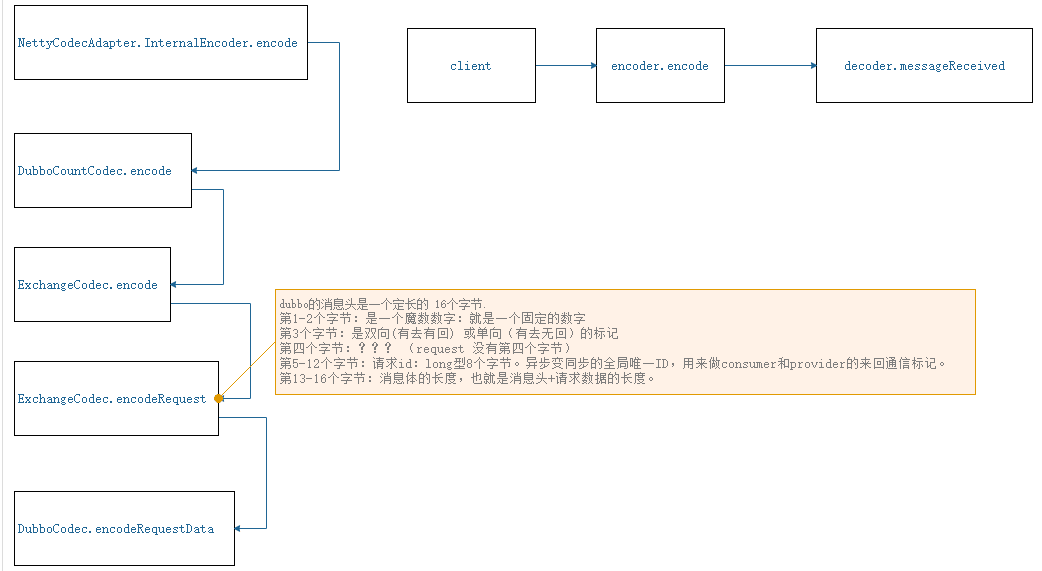
28-网络通信–编码解码之provider请求编码
网络通信–编码解码之provider请求编码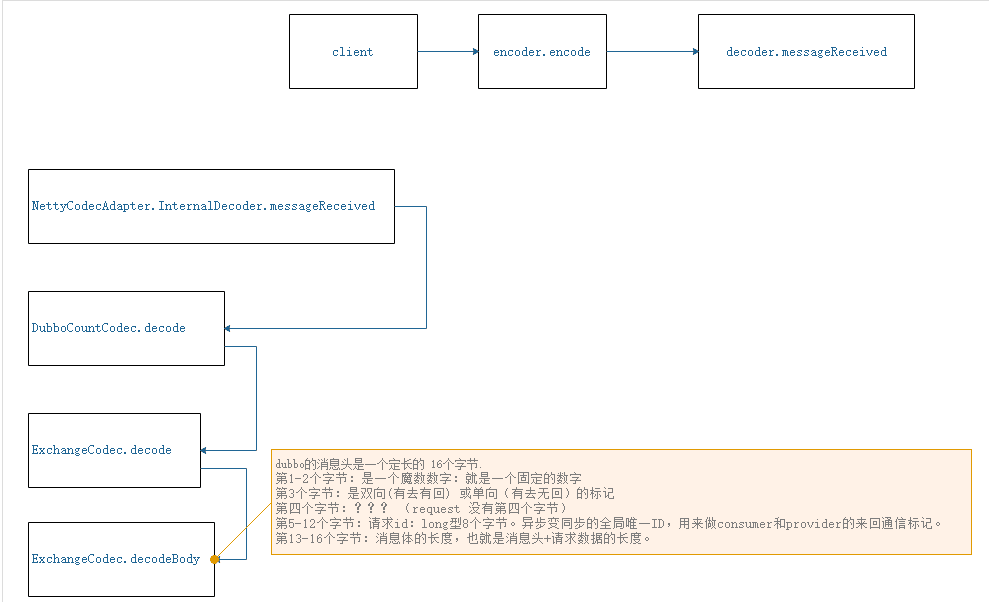
29-网络通信–编码解码之provider响应结果编码
网络通信–编码解码之provider响应结果编码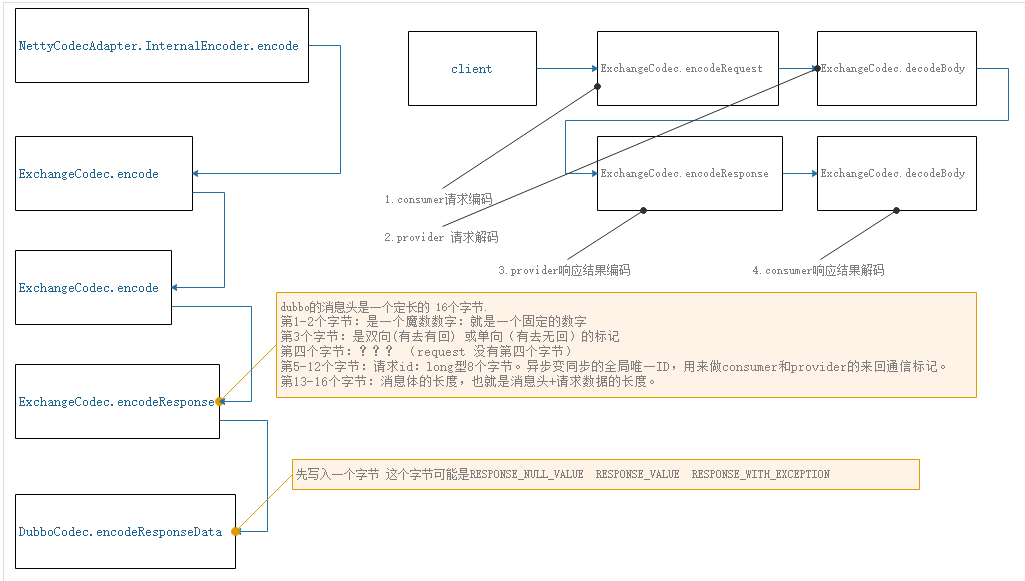
30-网络通信–编码解码之consumer响应结果编码
网络通信–编码解码之consumer响应结果编码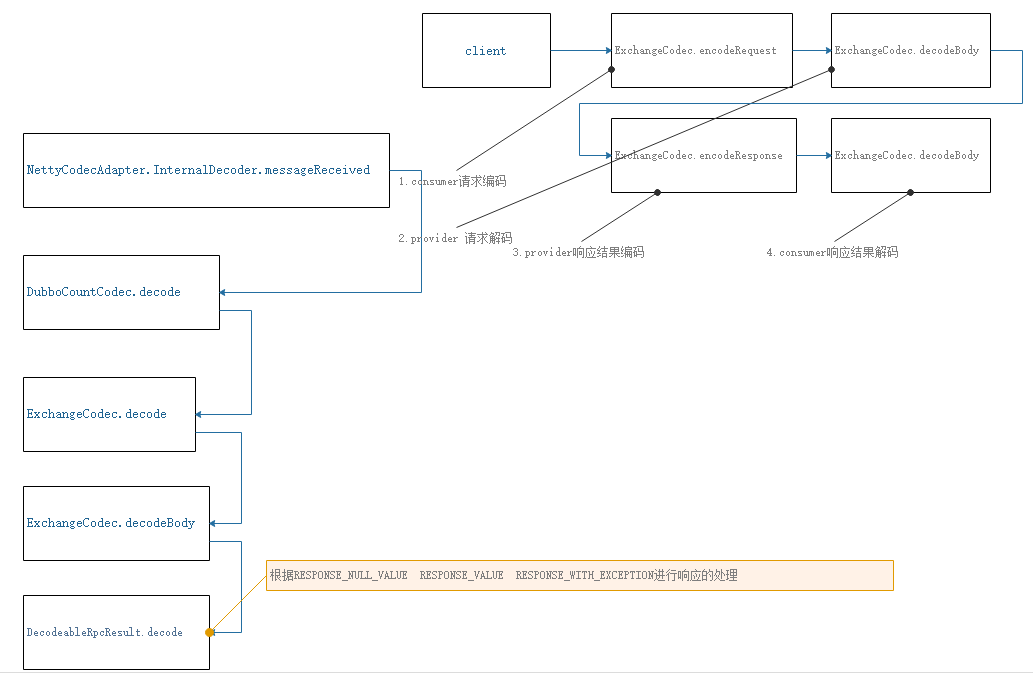
1.proxyFactory:就是为了获取一个接口的代理类,例如获取一个远程接口的代理。
它有2个方法,代表2个作用
a.getInvoker:针对server端,将服务对象,如DemoServiceImpl包装成一个Invoker对象。
b.getProxy :针对client端,创建接口的代理对象,例如DemoService的接口。
2.Wrapper:它类似spring的BeanWrapper,它就是包装了一个接口或一个类,可以通过wrapper对实例对象进行赋值 取值以及制定方法的调用。
3.Invoker:它是一个可执行的对象,能够根据方法的名称、参数得到相应的执行结果。
它里面有一个很重要的方法 Result invoke(Invocation invocation),
Invocation是包含了需要执行的方法和参数等重要信息,目前它只有2个实现类RpcInvocation MockInvocation
它有3种类型的Invoker
1.本地执行类的Invoker
server端:要执行 demoService.sayHello,就通过InjvmExporter来进行反射执行demoService.sayHello就可以了。
2.远程通信类的Invoker
client端:要执行 demoService.sayHello,它封装了DubboInvoker进行远程通信,发送要执行的接口给server端。
server端:采用了AbstractProxyInvoker执行了DemoServiceImpl.sayHello,然后将执行结果返回发送给client.
3.多个远程通信执行类的Invoker聚合成集群版的Invoker
client端:要执行 demoService.sayHello,就要通过AbstractClusterInvoker来进行负载均衡,DubboInvoker进行远程通信,发送要执行的接口给server端。
server端:采用了AbstractProxyInvoker执行了DemoServiceImpl.sayHello,然后将执行结果返回发送给client.
4.Protocol
1.export:暴露远程服务(用于服务端),就是将proxyFactory.getInvoker创建的代理类 invoker对象,通过协议暴露给外部。
2.refer:引用远程服务(用于客户端), 通过proxyFactory.getProxy来创建远程的动态代理类,例如DemoService的远程动态接口。
5.exporter:维护invoder的生命周期。
6.exchanger:信息交换层,封装请求响应模式,同步转异步。
7.transporter:网络传输层,用来抽象netty和mina的统一接口。
8.Directory:目录服务 StaticDirectory:静态目录服务,他的Invoker是固定的。 RegistryDirectory:注册目录服务,他的Invoker集合数据来源于zk注册中心的,他实现了NotifyListener接口,并且实现回调notify(Listurls),
整个过程有一个重要的map变量,methodInvokerMap(它是数据的来源;同时也是notify的重要操作对象,重点是写操作。)
为什么dubbo要自己设计一套SPI?
这是原始JDK spi的代码
ServiceLoaderserviceLoader=ServiceLoader.load(Command.class);
for(Command command:serviceLoader){
command.execute();
}
dubbo在原来的基础上设计了以下功能
1.原始JDK spi不支持缓存;dubbo设计了缓存对象:spi的key与value 缓存在 cachedInstances对象里面,它是一个ConcurrentMap
2.原始JDK spi不支持默认值,dubbo设计默认值:@SPI(“dubbo”) 代表默认的spi对象,例如Protocol的@SPI(“dubbo”)就是 DubboProtocol,
通过 ExtensionLoader.getExtensionLoader(Protocol.class).getDefaultExtension()那默认对象
3.jdk要用for循环判断对象,dubbo设计getExtension灵活方便,动态获取spi对象,
例如 ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(spi的key)来提取对象
4.原始JDK spi不支持 AOP功能,dubbo设计增加了AOP功能,在cachedWrapperClasses,在原始spi类,包装了XxxxFilterWrapper XxxxListenerWrapper
5.原始JDK spi不支持 IOC功能,dubbo设计增加了IOC,通过构造函数注入,代码为:wrapperClass.getConstructor(type).newInstance(instance),
dubbo为什么要设计adaptive?注解在类上和注解在方法上的区别?
adaptive设计的目的是为了识别固定已知类和扩展未知类。
1.注解在类上:代表人工实现,实现一个装饰类(设计模式中的装饰模式),它主要作用于固定已知类,
目前整个系统只有2个,AdaptiveCompiler、AdaptiveExtensionFactory。
a.为什么AdaptiveCompiler这个类是固定已知的?因为整个框架仅支持Javassist和JdkCompiler。
b.为什么AdaptiveExtensionFactory这个类是固定已知的?因为整个框架仅支持2个objFactory,一个是spi,另一个是spring
2.注解在方法上:代表自动生成和编译一个动态的Adpative类,它主要是用于SPI,因为spi的类是不固定、未知的扩展类,所以设计了动态$Adaptive类.
例如 Protocol的spi类有 injvm dubbo registry filter listener等等 很多扩展未知类,
它设计了Protocol$Adaptive的类,通过ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(spi类);来提取对象
SpringExtensionFactory的设计初衷
1.dubbo扩展未知类分为:spi 和spring
spi的扩展对象存储在SpiExtensionFactory
spring的扩展对象存储在 SpringExtensionFactory
2.SpringExtensionFactory的设计初衷:
a.设计的目的:方便开发者对扩展未知类的配置(可以用spi配置也可以spring bean实现)
b.SpringExtensionFactory在provider发布或consumer引用一个服务的时候,会把spring的容器托付给SpringExtensionFactory中去.
具体代码为:ReferenceBean.setApplicationContext 和 ServiceBean.setApplicationContext
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
SpringExtensionFactory.addApplicationContext(applicationContext);
}
c.当SpiExtensionFactory没有获取到对象的时候会遍历SpringExtensionFactory中的spring容器来获取要注入的对象.具体代码:AdaptiveExtensionFactory.getExtensionpublicT getExtension(Classtype, String name) {
for (ExtensionFactory factory : factories) {
T extension = factory.getExtension(type, name);
if (extension != null) {
return extension;
}
}
return null;
}
3.SpringExtensionFactory目前的作用?SpringExtensionFactory前期的设计初衷非常好,但是后来执行偏离了,没有按这个初衷去落地。因为从这SpringExtensionFactory.getExtension代码(如下:)可以看出,是从ApplicationContext获取对象的。
publicT getExtension(Classtype, String name) {
for (ApplicationContext context : contexts) {
if (context.containsBean(name)) {
Object bean = context.getBean(name);
if (type.isInstance(bean)) {
return (T) bean;
}
}
}
return null;
}
但是目前这套系统没有配置spring对象的任何痕迹;甚至连配置自定义filter类,也无法实现spring bean配置,只能spi配置。